Neither one nor Many
Software engineering blog about my projects, geometry, visualization and music.
Sometimes as a webdeveloper I have to work with websites where performance is not optimal and sacrifised in exchange for some other quality attribute.
Perhaps that's why I "over optimize" some sites--like this blog--which probably is not even worth the effort considering the traffic it gets.  However, it's something I spend my time on and it could be useful to others. And this being a blog, I blog about it.
However, it's something I spend my time on and it could be useful to others. And this being a blog, I blog about it.
Statically compile
In this blog I statically "compile" this websit with a minimalist tool I created. It was a project with a similar approach as octopress (based on Jekyll). I've never used octopress, I'm not sure if it even existed back when starting this blog.
A webserver likes plain file serving more than CPU intensive PHP scripts (that generate pages per request). You may not need to statically compile everything like I do, there are alternatives like using Varnish cache to optimize your performance perhaps. Tweakers.net (and many more high performance websites) use Varnish.
YSlow & Page Speed diagnostiscs
These are browser plugins, but you can do the checks online via services like: GTmetrix or WebPageTest. In the following screenshot are as an example some quick wins I made using GTmetrix in two ours of optimizing my blog.
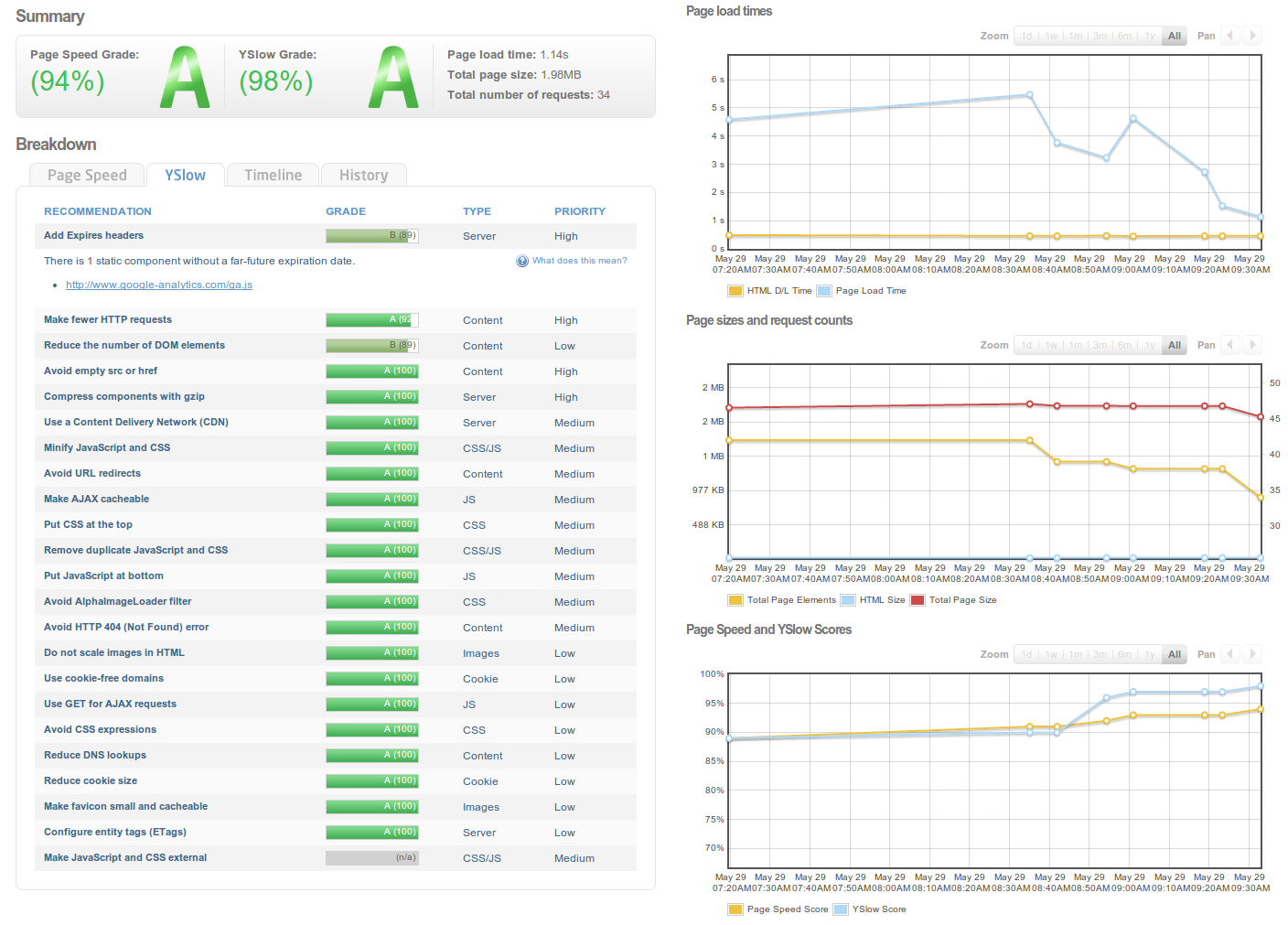
In this blog I won't go over all the Tips given on those websites, but there is a lot of useful advice in there I won't repeat. Except for maybe one more: Caching headers for clients (and (caching) proxies), you might want to make sure you get those right. ![]()
Cloudfront as a Content Delivery Network (CDN)
In google analytics I noticed that in some countries my blog was a lot slower. Especially the loading of media.
I verified this with WebPageTest, apparently my AWS server that was located in Ireland was too far away for some countries. Maybe not especially slow for the HTML, but especially for media, like images, a.k.a. "Content". Hence, CDN ![]()
First how to setup a CDN with Cloudfront...
You start with creating an "S3" bucket, which is basically a "dumb" but fast hosting for files. For every file you put there you have to set permissions, headers (if you want those headers to be returned to the client (i.e. Content-Type, etc.)). Normally a webserver like apache would do most of that stuff for you, here you have to do it yourself. All your static content should be uploaded to such a bucket.
Your bucket is something named like <BUCKETNAME>.s3-website-eu-west-1.amazonaws.com.
As you can guess from the domain name, the bucket is hosted in one location. With "one location" I mean the unique URL, but also "EU West 1", which is one region (or location).
Files in the bucket are accessible via HTTP: //cdn-cppse-nl.s3-website-eu-west-1.amazonaws.com/some/path/to/a/file.txt.
If you put Cloudfront in front of your bucket, you can make if fetch from your bucket, and "cache" it in X locations all over the world. Your cloudfront endpoint is something like <UNIQUEID>.cloudfront.net.
When you want to use another domain in your HTML, you can define a CNAME (canonical name, a hostname that resolves to another hostname basically), which is a dns record that points to the cloudfront.net domain. In my case cdn.cppse.nl points to d15zg7znhuffnz.cloudfront.net (which reads from cdn-cppse-nl.s3-website-eu-west-1.amazonaws.com).
Creating a CNAME has the advantage that you can at DNS level switch to another CDN. If I were to use akamai, I can make the CNAME point to something from akamai. I could also prepare a totally new bucket and/or cloudfront endpoint, and then switch to the new endpoint by changing the CNAME to another <UNIQUEID2>.cloudfront.net.
Second how Cloudfront / CDNs work...
Cloudfront hostname resolves to multiple IP addresses. At DNS level the actual "edge" (a.k.a. server, in terms of it's ip address) is chosen where the actual files are to be fetched from. You can interpret all the cloudfront edges as "mirrors" for your S3 bucket. On my home PC (which is currently near Amsterdam) when I resolve cdn.cppse.nl (d15zg7znhuffnz.cloudfront.net) it is resolved to a list of IP's:
> cdn.cppse.nl
Server: 127.0.1.1
Address: 127.0.1.1#53
Non-authoritative answer:
cdn.cppse.nl canonical name = d15zg7znhuffnz.cloudfront.net.
Name: d15zg7znhuffnz.cloudfront.net
Address: 54.230.13.72
Name: d15zg7znhuffnz.cloudfront.net
Address: 54.230.12.206
Name: d15zg7znhuffnz.cloudfront.net
Address: 54.230.12.246
Name: d15zg7znhuffnz.cloudfront.net
Address: 54.230.13.12
Name: d15zg7znhuffnz.cloudfront.net
Address: 54.230.13.65
Name: d15zg7znhuffnz.cloudfront.net
Address: 54.230.12.249
Name: d15zg7znhuffnz.cloudfront.net
Address: 54.230.13.2
Name: d15zg7znhuffnz.cloudfront.net
Address: 54.230.15.34The fastest "edge" for my location is returned first and has the address: 54.230.13.72.
If you reverse DNS lookup that IP you can see "ams1" in the hostname the ip resolved too.
> 54.230.13.72
Server: 127.0.1.1
Address: 127.0.1.1#53
Non-authoritative answer:
72.13.230.54.in-addr.arpa name = server-54-230-13-72.ams1.r.cloudfront.net.
Authoritative answers can be found from:
This is specific to how Amazon structures their hostnames. ams1 in server-54-230-13-72.ams1.r.cloudfront.net stands for Amsterdam Airport Schiphol. Their coding is based on the closest International Airport IATA code.
You can check how the domain resolves and what latency/packetloss is from a lot of different "checkpoints" (locations) at once, with tools like APM Cloud Monitor. In China/Hong Kong the address it resolves to is: 54.230.157.116. The reverse dns resolution for that ip is server-54-230-157-116.sin3.r.cloudfront.net, where SIN is the code for Republic of Singapore. So they won't have to download my javascript/css/media there all the way from Amsterdam.
If your website is entirely static, you could host everything this way. And hopefully people from all over the world can benefit from fast downloads from their nearest edges.
A few challenges I had with Cloudfront
After switching to Cloudfront I first noticed that loadtimes increased! ![]() I forgot that my apache used
I forgot that my apache used mod_gzip (and mod_deflate) to send text-based content compressed to the http client/webbrowser. But I uploaded my stuff to S3 "as is", which is plain/text and not gzipped.
A webbrowser normally sends in it's request whether it supports gzip or deflate encoding. If it does, apache will compress the content in a way to the client's preference, otherwise it will serve the content "as is". S3 is simply a key-value store in a way, so this conditional behaviour based on a client's headers like Accept-Encoding:gzip,deflate,sdch isn't possible. In the documentation you see that you have to create separate files.
Unfortunately Javascript doesn't have access to the browsers Accept-Encoding header (that one my chromium sends). So you cannot document.write the correct includes based on this client-side. That was my first idea.
How I now resolved it: For the CSS and Javascript files served from Cloudfront, I upload the plain version file.css and a compressed version file.gz.css. With correct headers etc., like this:
# Create expiry date
expir="$(export LC_TIME="en_US.UTF-8"; date -u +"%a, %d %b %Y %H:%M:%S GMT" --date "next Year")"
# Copy global.js to global.gz.js and gzip compress the copy
cp -prv global.js global.gz.js
gzip -9 global.gz.js
# Upload the files to bucket
s3cmd --mime-type=text/css \
--add-header="Expires:$expir" \
--add-header=Cache-Control:max-age=31536000 \
-P put global.js s3://cdn-cppse-nl/global.js
s3cmd --mime-type=text/css \
--add-header=Content-Encoding:gzip \
--add-header="Expires:$expir" \
--add-header=Cache-Control:max-age=31536000 \
-P put global.gz.js s3://cdn-cppse-nl/global.gz.jss3cmd is awesome for uploading stuff to s3 buckets. It also has a very useful sync command.
Perfect routing
Because I now have separate files for compressed and uncompressed javascript/css files, I cannot serve my static HTML files "blindly" from my CDN anymore.
I now have to make sure I send the HTML either with references to file.gz.css or file.css based on the client's browser request headers.
So I introduced "Perfect routing", okay, I'm kind of trolling with the "Perfect" here, but I use "perfect hash generation" with gperf. ![]() At compiletime I output an input file for gperf and have gperf generate a hash function that can convert an
At compiletime I output an input file for gperf and have gperf generate a hash function that can convert an article name string (the Request URI) to an Index (or to nothing in case the request is invalid).
That Index points directly to the position in a map that it also generates containing the filename that corresponds to the article name. In that way it can fetch the file in a single lookup, and the filesystem is never hit for invalid requests.
My routing.cgi program does the following:
- Read the
Accept-Encodingheader from the client. - If the generated hash function returns the filename: read the HTML into memory.
- If client requested gzip encoding: replace in the HTML javascript and CSS includes with a regex to their
.gz.jsversions. Compress the HTML itself too in the same encoding. - If client requested deflate encoding: do the same with deflate encoding on the HTML, but I currently didn't implement
.defl.jsversions for the Javascript and CSS. - Also after fixing the javascript and CSS includes, compress the HTML now in the same way (gzip or deflate).
- For fun it will add a
X-Compressionheader with compression ratio info. - If the compressed length exceeds the plain version, it will use the plain version.
routing.cgi apache 2.4 config
For now routing.cgi is a simple cgi program, it could be further optimized by making it an apache module, or perhaps using fastcgi.
AddHandler cgi-script .cgi
ScriptAlias /cgi-bin/ "/srv/www/vhosts/blog.cppse.nl/"
<Directory "/srv/www/vhosts/blog.cppse.nl/">
AllowOverride None
Options +ExecCGI -Includes
Order allow,deny
Allow from all
Require all granted
DirectoryIndex /cgi-bin/routing.cgi
FallbackResource /cgi-bin/routing.cgi
</Directory>routing.cpp a few code snippets
1) Determine encoding:
char *acceptEncoding = getenv("HTTP_ACCEPT_ENCODING");
enum encodings {none, gzip, deflate};
encodings encoding = none;
if (acceptEncoding) {
if (strstr(acceptEncoding, "gzip"))
encoding = gzip;
else if (strstr(acceptEncoding, "deflate"))
encoding = deflate;
}2) The hash lookup:
static struct knownArticles *article = Perfect_Hash::in_word_set(requestUri, strlen(requestUri));
if (article) {
printf("X-ArticleId: %d\n", article->articleid);
printf("X-ArticleName: %s\n", article->filename);
printf("Content-Type: text/html; charset=utf-8\n");
....
ss << in.rdbuf();
} else {
printf("Status: 404 Not Found\n");
printf("Content-Type: text/html; charset=utf-8\n");
ss << "404 File not found";
}3) The regexes:
if (encoding == gzip) {
//std::regex regx(".css");
//str = std::regex_replace(str, regx, string(".gz.css"));
const boost::regex scriptregex("(<script[^>]*cdn.cppse.nl[^ ]*)(.js)");
const boost::regex cssregex("(<link[^>]*cdn.cppse.nl[^ ]*)(.css)");
const std::string fmt("\\1.gz\\2");
str = boost::regex_replace(str, scriptregex, fmt, boost::match_default | boost::format_sed);
str = boost::regex_replace(str, cssregex, fmt, boost::match_default | boost::format_sed);
cstr.assign(compress_string2(str));
}4) Compressing to gzip or deflate:
I simply took of Timo Bingmann his {de}compress_string functions, whom use deflate, and created gzip versions of these.
They took me a while to get right, to find the correct parameters etc., so you may find them useful.
You can find them here: Deflate and Gzip Compress- and Decompress functions.
More "performance wins": deferred javascript loading
As a base for the html I use adaptiv.js which provides a grid layout for a responsive design, with the following config:
// Find global javascript include file
var scripts = document.getElementsByTagName('script'),
i = -1;
while (scripts[++i].src.indexOf('global') == -1);
// See if we're using gzip compression, and define config for adaptiv.js
var gzip = scripts[i].src.indexOf('.gz.js') != -1,
rangeArray = gzip
? [
'0px to 760px = mobile.gz.css',
'760px to 980px = 720.gz.css',
'980px to 1280px = 960.gz.css',
'1280px = 1200.gz.css',
]
: [
'0px to 760px = mobile.css',
'760px to 980px = 720.css',
'980px to 1280px = 960.css',
'1280px = 1200.css'
];Only after loading the javascript will it correctly "fix" the right css include, introducing an annoying "flicker" effect. This makes it necessary to require the adaptiv.js javascript asap (a.k.a. in the header of the page).
To fix this I simply added the same css includes with media queries:
<link href='//cdn.cppse.nl/global.css' rel='stylesheet'>
<link href='//cdn.cppse.nl/assets/css/960.css' media='only screen and (min-width: 980px) and (max-width: 1280px)' rel='stylesheet'>
<link href='//cdn.cppse.nl/assets/css/720.css' media='only screen and (min-width: 760px) and (max-width: 980px)' rel='stylesheet'>
<link href='//cdn.cppse.nl/assets/css/1200.css' media='only screen and (min-width: 1280px)' rel='stylesheet'>
<link href='//cdn.cppse.nl/assets/css/mobile.css' media='only screen and (min-width: 0px) and (max-width: 760px)' rel='stylesheet'>Now the javascript in adaptiv.js is only a fallback for browsers that don't support these queries.
All javascript can now be included after DOM elements are loaded/rendered. Nowadays there may be different libraries that don't have this problem. But I'm not up-to-date on that ![]() .
.
As long as you make sure the javascript is loaded after all elements are drawn.
Personally I don't put do that in the <body>'s onload="" attribute, as that is executed after everything on your page is loaded. I prefer to put it right before the body tag closes (</body>), as only the static DOM should have been outputted for the browser.
(You may want your javascript photo-viewer loaded before the very last thumbnail is done loading for example.)
// Now start loading the javascript...
var j = document.createElement('script');
j.type = 'text/javascript';
j.src = '//cdn.cppse.nl/global.' + (gzip ? 'gz.' : '') + 'js?' + version;
document.body.appendChild(j);You can also do this for certain stylesheets, like the print.css perhaps.
Image compression
Another huge gain is of course compressing images. I have PNG, JPG and GIF images. Before I choose a format I already try to choose the most appropriate encoding. Typically PNG or GIF for screenshots, JPG for everything else. In my static site generation, I also optimize all images.
TruePNG + PNGZopfli are the best for lossless compression, see this awesome comparison.
They are windows tools, but they run perfectly with wine, albeit a little slower that's how I use them.
For gifs I use gifsicle (apt-get install gifsicle), and for JPG jpegoptim (apt-get install jpegoptim).
minimize_png:
wine /usr/local/bin/TruePNG.exe /o4 "file.png"
wine /usr/local/bin/PNGZopfli.exe "file.png" 15 "file.png.out"
mv "file.png.out" "file.png"
minimize_jpg:
jpegoptim --strip-all -m90 "file.jpg"
minimize_gif:
gifsicle -b -O3 "file.gif"Excerpt from minimize.log:
compression of file 86-large-thumb-edges.png from 96K to 78K
compression of file 86-edges.png from 45K to 35K
compression of file 86-thumb-edges.png from 38K to 31K
compression of file 600width-result.png from 1,3M to 121K
compression of file 72-large-thumb-userjourney.jpg from 100K to 29K
compression of file 57-large-thumb-diff_sqrt_carmack_d3rsqrt.jpg from 557K to 95K
compression of file 63-result.jpg from 270K to 137K
compression of file 55-large-thumb-vim.jpg from 89K to 27KReplace google "Custom search" with something "faster"
Google's custom search is pretty useful and easy to setup. I did have to do a few nasty CSS hacks to integrate it in my site the way I wanted.
- The advantage is that is does the crawling automatically.
- The disadvantage is that it does the crawling automatically.
- Another disadvantage is that it adds a lot of javascript to your site.
In my case when I search for a keyword "foobar", google search would yield multiple hits:
/index- main page/blog- category/1- paging/foobar- individual article
Wanting more control I switched to Tokyo Dystopia ![]() . You can see it in action when searching via the searchbox on top of the page.
For this to work I now also generate a "searchdata" outputfile alongside the HTML, which is simply the "elaborated" Markdown text. With elaborated I mean code snippets and user comments included.
. You can see it in action when searching via the searchbox on top of the page.
For this to work I now also generate a "searchdata" outputfile alongside the HTML, which is simply the "elaborated" Markdown text. With elaborated I mean code snippets and user comments included.
CSS and Javascript minification
Not going into detail on this one. As a tool I use mince, which by default provides css and js minification with with csstidy and jsmin. For javascript I made a small adjustment to make it use crisp (who is an old collegue of mine)'s JSMin+. Because it's a more advanced minifier that yields even smaller javascript files.
Deferred loading of embedded objects like YouTube videos
I found YouTube/Vimeo & Other flash embeds in my blog posts annoyingly slow. So what I do is put the actual embed code in a container as an HTML comment. For example: I have a custom video player for an mp4 stream like this:
<p><center>
<a class="object_holder" href="#" onclick="videoInLink(this)" style="background:url(//cdn.cppse.nl/83-videothumb.png); width: 750px; height:487px; display:block;">
<!--
<object id="player" classid="clsid:D27CDB6E-AE6D-11cf-96B8-444553540000" name="player" width="750" height="487">
<param name="movie" value="//cdn.cppse.nl/player.swf" />
<param name="allowfullscreen" value="true" />
<param name="allowscriptaccess" value="always" />
<param name="flashvars" value="file=//blog.cppse.nl/videos/wxhttpproxy.mp4&repeat=never&shuffle=true&autostart=true&streamer=lighttpd&backcolor=000000&frontcolor=ffffff" />
<embed
type="application/x-shockwave-flash"
id="player2"
name="player2"
src="//cdn.cppse.nl/player.swf"
width="750"
height="487"
allowscriptaccess="always"
allowfullscreen="true"
flashvars="file=//blog.cppse.nl/videos/wxhttpproxy.mp4&repeat=never&shuffle=true&autostart=true&streamer=lighttpd&backcolor=000000&frontcolor=ffffff"
/>
</object>
-->
</a>
</center></p>The object_holder displays a screenshot of the player, giving the illusion it's already loaded. Only when the user clicks the screenshot the commented <object> is inserted using the videoInLink javascript function.
function videoInLink(anchor)
{
anchor.innerHTML = anchor.innerHTML.replace('<!--','').replace('-->','');
anchor.removeAttribute('href');
anchor.onclick = null;
return false;
} The end
Concluding my ramblings, I hope you may have find something of use in this post.


Topics:
Other interests:
EBPF Flamegraphs C++ Ubuntu 20.04
Site generated using ![]() ArticleManager © 2010-2013
ArticleManager © 2010-2013

rayburgemeestre
2014-06-01 20:33:44
In those cases you can use the "Vary: Accept-Encoding" header, to make sure it will cache a resource uniquely for each "Accept-Encoding" value.
See: http://blog.maxcdn.com/accept-encoding-its-vary-important/ @:)@