Neither one nor Many
Software engineering blog about my projects, geometry, visualization and music.
Auto Login for OpenStack Dashboard
For some reason Lastpass cannot remember the OpenStack dashboard, maybe there is something wrong with the HTML markup, I didn't investigate. This script is just to auto login whenever I'm logged out (which happens every hour or so)
Script here: https://cppse.nl/public/openstack-auto-login-dashboard.js
Include priorities in JIRA dashboards
See my blog post "Visualize Issue Ranks in Atlassian Jira Agile board".
Script here: https://cppse.nl/public/tampermonkey_agile_board_prios.js
Make input boxes readable everywhere
My dark gnome theme screwed up lot's of input boxes on Firefox, because they would become dark grey with black text. Not that handy.
Script here: https://cppse.nl/public/fix-textareas-blue-bg.js
Include time spent per day in Kanbanflow
I used to use this a lot, log pomodoros on my ticket representations in Kanbanflow, which I used to export to JIRA tempo hours.. (these days I have a different approach)
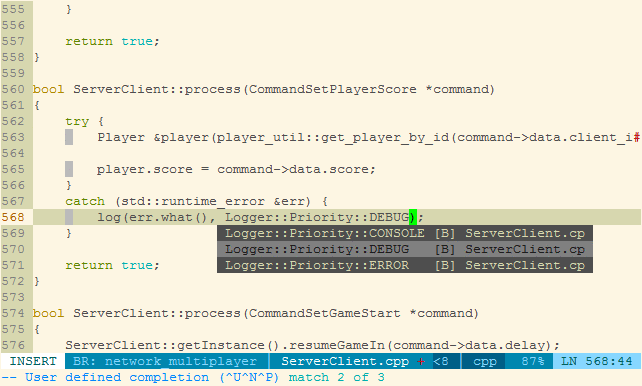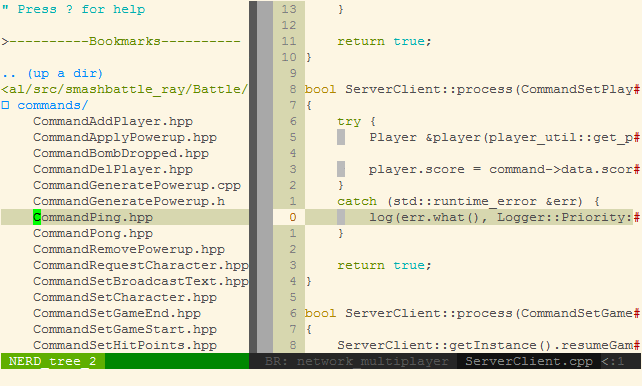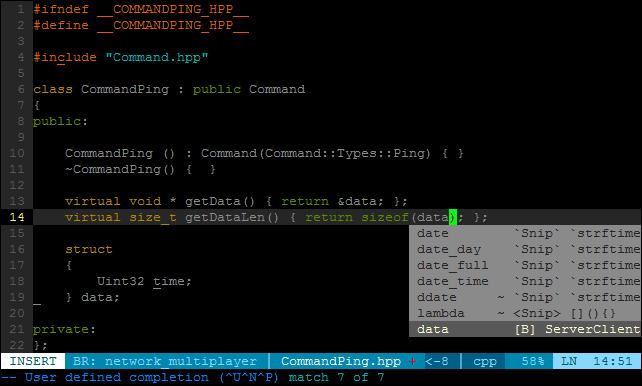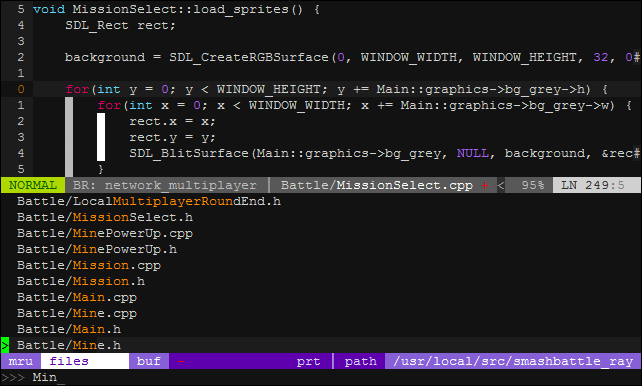
Script here: https://cppse.nl/public/tampermonkey_kanbanflow_time_spent_per_day.js
Track pomodoro's on Kanbanflow
Script here: https://cppse.nl/public/track-pomodoros-kanbanflow.js
Fix ugly description boxes on Kanbanflow
Script here: [https://cppse.nl/public/fix-ugly-description-boxes-kanbanflow.js][7]
[7]:

Created a "Lame PHP Parser" that in this picture visualizes it's own sourcecode! ")
I thought the output was pretty cool.
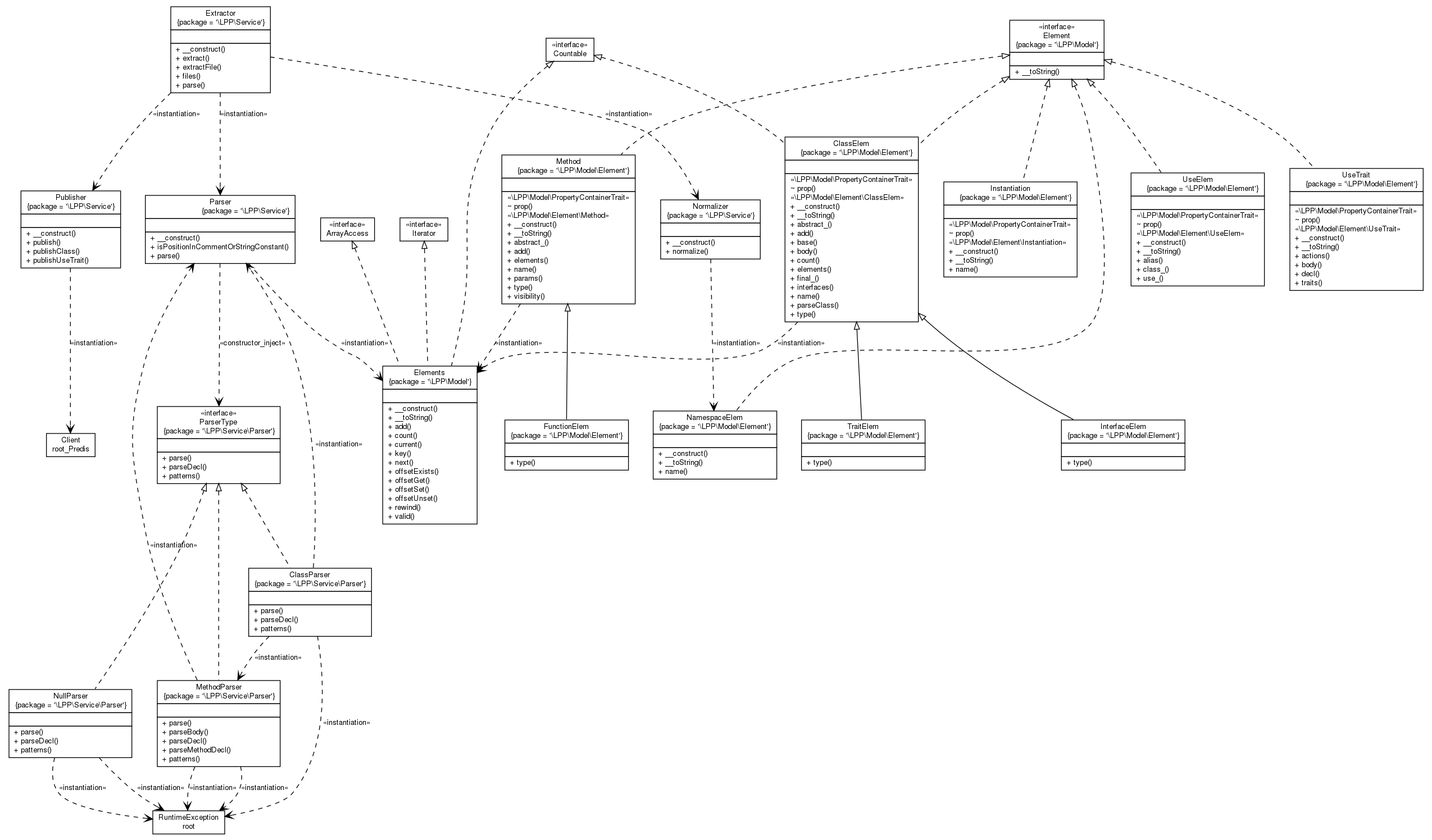
It's not the most efficient code, which is fine for my current use case. I was wondering if I could speed it up with Facebook's HHVM (HipHop VM), a PHP virtual machine.
HipHop VM executes the code 5,82 times faster!(*)
Parsing the Symfony code in my 'vendor' directory, takes ~57 seconds with the PHP executable provided by Ubuntu.
PHP 5.5.3-1ubuntu2.1 (cli) (built: Dec 12 2013 04:24:35)
Copyright (c) 1997-2013 The PHP Group
Zend Engine v2.5.0, Copyright (c) 1998-2013 Zend Technologies
with Zend OPcache v7.0.3-dev, Copyright (c) 1999-2013, by Zend TechnologiesBenchmarks from three successive runs:
- real 0m57,34s, user 0m56,75s, sys 0m0,29s
- real 0m57,18s, user 0m56,58s, sys 0m0,28s
- real 0m58,38s, user 0m57,72s, sys 0m0,34s
Parsing the same directory three times with hhvm.
HipHop VM 3.0.1 (rel)
Compiler: tags/HHVM-3.0.1-0-g97c0ac06000e060376fdac4a7970e954e77900d6
Repo schema: a1146d49c5ba0d6db903beb3a4ed8a3766fef182Benchmarks from three successive runs:
- real 0m9,86s, user 0m9,04s, sys 0m0,54s
- real 0m9,85s, user 0m9,15s, sys 0m0,45s
- real 0m9,74s, user 0m9,06s, sys 0m0,44s
(*) 57.34 / 9.86 = 5,815415822
Solving the puzzle at PHPBenelux 2014

Last conference at the Dutch PHP Conference (DPC) I wrote a summary (in Dutch). This time I couldn't find the time, I took notes though, but I was/am too lazy. For PHP Benelux 2014 experiences you can read on other people their blogs, for example the one David wrote at his blog. And if you're looking for sheets, chances are you can find them at the event's joind.in page.
I made one big mistake at PHPBenelux, that was missing (by accident (don't ask why :p)) Ross Tuck's talk. Was really curious about that one. Of the other talks I especially liked Bastian Hofmann's talk "Marrying front with back end". His talk at DPC was also very good IIRC.
Dutch web alliance puzzle
An old collegue of mine (Marijn) and I decided to programmatically solve the puzzle created for the event there DWA. You can find the puzzle instructions in the photo I took (see fig.2.) We heard a rumour that you could win an ipad if you solved it. Unfortunately that wasn't true . In short you have to place all cubes side-by-side in such a way that rotating them combined should yield four unique labels each rotation step. There is only one possible solution.
We decided both on different approaches and see who would solve it first. Challenge accepted! I lost unfortunately, I even had to abandon my first approach and made the switch to semi-brute-force as soon as I gained more insight in how it could be solved more easily this way. Marijn approached it brute force from the start.
I gave each cube a number {1, 2, 3, 4}, and each sidename a letter {a, b, c, d, x, y}. Next I defined for each cube three directions {a, b, c, d}, {x, b, y, d} and {x, c, y, a} (see fig.1.). All these directions can also be in reverse ({d, c, b, a}, ...).
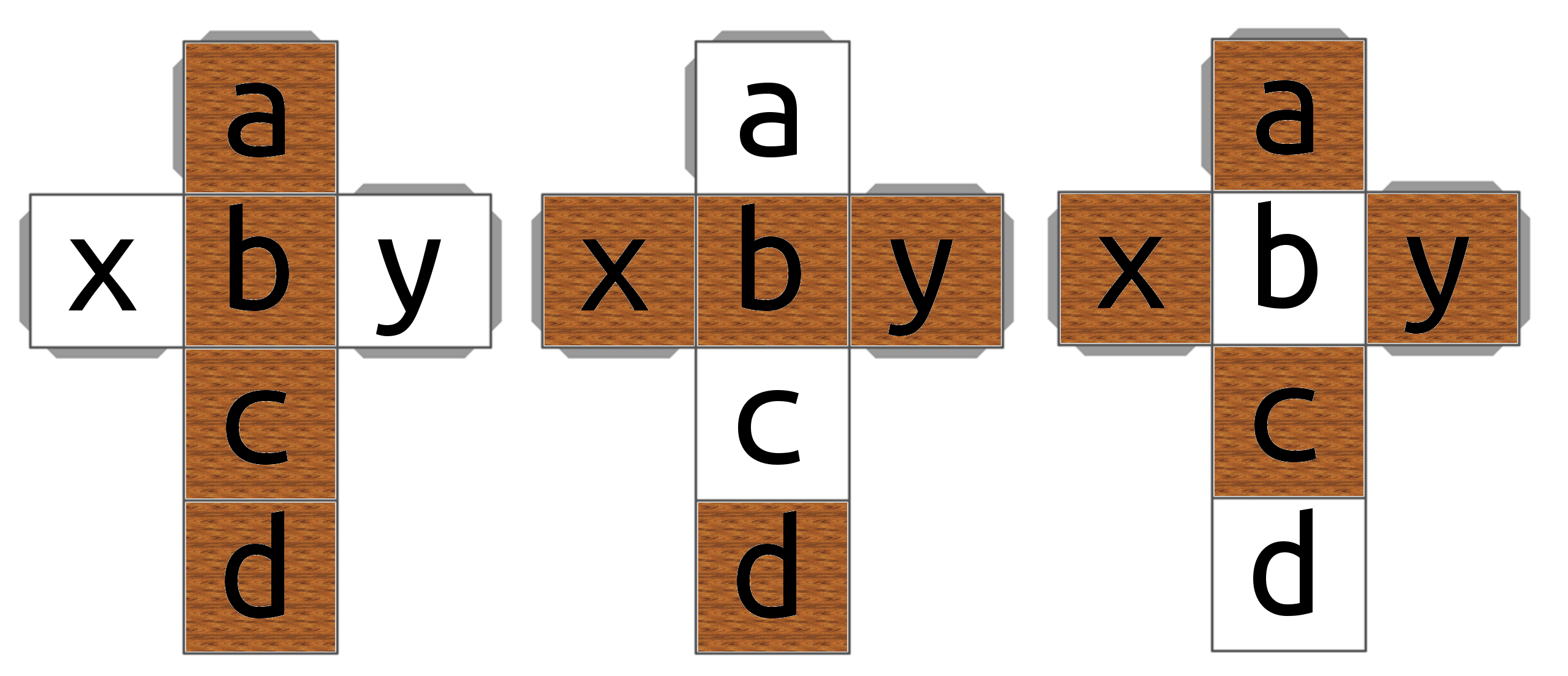

My first idea was to place a cube on a side randomly, choosing for each cube a random direction to rotate in, and try four rotation steps. If in all steps the pictures were unique that would be a solution.
I made a mistake in the implementation, totally forgot that {x, c, y, a} is also a possible sequence. What also didn't help is that I misread the instructions at first, thinking all sides had to be equal (instead of not-equal), which isn't possible if you take a good look at the actual cubes. I guess beer + coding isn't always a good combination.
My second approach was simply, generate "layouts" for each cube's three directions, i.e. for {a, b, c, d}:
{a, b, c, d}{b, c, d, a}{c, d, a, b}{d, a, b, c}{d, c, b, a}{c, b, a, d}{b, a, d, c}{a, d, c, d}
For each cube a, b, c, d mean different side types (the different logos, php, phpbenelux, dwa, phpelephant). I simply compare every combination, and filter out the duplicate results. You initially get eight solutions, because every solution you can start at the first, second, third or fourth "step" of the solution, and eight because of the extra "times two" multiplier you get for forward versus backward rotation.
Solver in C++
Code also available on http://ideone.com/ttFYMD.
#include <iostream>
#include <algorithm>
#include <stdexcept>
#include <string>
#include <sstream>
#include <vector>
#include <array>
#include <iomanip>
enum class sidename
{
a, b, c, d, x, y
};
enum class sidetype
{
phpbenelux, php, phpelephant, dwa
};
std::string sidename_str(sidename sn) {
switch (sn) {
case sidename::a: return "a";
case sidename::b: return "b";
case sidename::c: return "c";
case sidename::d: return "d";
case sidename::x: return "x";
case sidename::y: return "y";
}
throw std::runtime_error{"invalid sidename"};
}
std::string sidetype_str(sidetype st) {
switch (st) {
case sidetype::phpbenelux: return "phpbenelux";
case sidetype::php: return "php";
case sidetype::phpelephant: return "phpelephant";
case sidetype::dwa: return "dwa";
}
throw std::runtime_error{"invalid sidetype"};
}
/**
* cubes define 6 side types (or pictures)
*
* cubes calculate for themselves all possible layouts, meaning
* if you rotate them into some direction, you get a side, followed by side+1, side+2, side+3.
* there are a few possibilities: reverse order, and in each layout (or "path") you can start
* rotating the cube on side, side+1, side+2 or side+4 (starting point "shifts").
*/
class cube
{
public:
cube(sidetype a, sidetype b, sidetype c, sidetype d, sidetype x, sidetype y)
: a_{a}, b_{b}, c_{c}, d_{d}, x_{x}, y_{y},
directionnames_({{
{sidename::a, sidename::b, sidename::c, sidename::d},
{sidename::x, sidename::b, sidename::y, sidename::d},
{sidename::a, sidename::y, sidename::c, sidename::x} }}),
directions_({{ {a, b, c, d}, {x, b, y, d}, {a, y, c, x} }})
{
for (int i=0; i<4; i++) {
for (auto &sides : directions_) {
// normal insert
layouts_.push_back(sides);
// reverse insert
auto sidesrev = sides;
std::reverse(std::begin(sidesrev), std::end(sidesrev));
layouts_.push_back(sidesrev);
// shift all
sidetype temp = sides[0];
for (int i=1; i<=3; i++)
sides[i - 1] = sides[i];
sides[3] = temp;
}
}
}
const std::vector<std::array<sidetype, 4>> & layouts() { return layouts_; }
private:
/**
* This is how I labeled each sidetype:
*
* X = a
* X X X = x b y
* X = c
* X = d
*/
sidetype a_;
sidetype b_;
sidetype c_;
sidetype d_;
sidetype x_;
sidetype y_;
std::array<std::array<sidename, 4>, 3> directionnames_;
std::array<std::array<sidetype, 4>, 3> directions_;
std::vector<std::array<sidetype, 4>> layouts_;
};
/**
* helper class that can see if a given solution is a duplicate from a previous solution
*
* if you have a solution that is simply the same one, but rotating in a different direction
* is not really a new solution. also note the four possible starting point in each layout/path.
* so it will check if duplicates exist in both forward and backward directions, and for each
* possible four shifts
*/
class solutions
{
public:
solutions()
{}
bool is_dupe(std::array<std::array<sidetype, 4>, 4> temp2)
{
// Check if found solution isn't a duplicate
bool duplicate = false;
for (auto &solution : solutions_) {
for (int j=0; j<8; j++) {
duplicate = true;
int sidenum = 0;
for (auto &side : solution) {
auto &temp = temp2[sidenum++];
int count = 0;
int offset = j % 4;
if (j < 4) {
// Check if they are duplicates, as we use offsets of +0, +1, +2, +3 we can
// detect shifted duplicate results.
for (auto i = side.begin(); i != side.end(); i++) {
duplicate = duplicate && temp[(count + offset) % 4] == *i;
count++;
}
}
else {
// Check if they are duplicates simply in reverse order, also with the
// detect for shifted duplicates.
for (auto i = side.rbegin(); i != side.rend(); i++) {
duplicate = duplicate && temp[(count + offset) % 4] == *i;
count++;
}
}
}
if (duplicate)
return true;
}
}
// Remember found solution, for duplicates checking
solutions_.push_back(temp2);
return false;
}
private:
std::vector<std::array<std::array<sidetype, 4>, 4>> solutions_;
};
int main (int argc, char *argv[])
{
/*
* on the sheet:
*
* cube 4 (sideways)
*
* cube 1, 2, 3
*/
cube one{
sidetype::dwa,
sidetype::phpelephant,
sidetype::phpbenelux,
sidetype::dwa,
sidetype::php,
sidetype::phpbenelux};
cube two{
sidetype::phpelephant,
sidetype::phpbenelux,
sidetype::phpbenelux,
sidetype::phpbenelux,
sidetype::php,
sidetype::dwa};
cube three{
sidetype::phpbenelux,
sidetype::dwa,
sidetype::phpelephant,
sidetype::php,
sidetype::dwa,
sidetype::phpelephant};
cube four{
sidetype::php,
sidetype::phpelephant,
sidetype::phpbenelux,
sidetype::phpelephant,
sidetype::dwa,
sidetype::php};
solutions solution;
for (auto &cube1sides : one.layouts()) {
for (auto &cube2sides : two.layouts()) {
for (auto &cube3sides : three.layouts()) {
for (auto &cube4sides : four.layouts()) {
// Pictures have to be unique on each four cubes to be considered a unique solution..
bool flag = false;
for (int i=0; i<4; i++) {
// .. Also on each four rotations of course
flag = flag || (!(cube1sides[i] != cube2sides[i] &&
cube1sides[i] != cube3sides[i] &&
cube1sides[i] != cube4sides[i] &&
cube2sides[i] != cube3sides[i] &&
cube2sides[i] != cube4sides[i] &&
cube3sides[i] != cube4sides[i]));
}
if (!flag){
// Skip duplicate solutions
if (solution.is_dupe({cube1sides, cube2sides, cube3sides, cube4sides})) {
continue;
}
// Print the result
std::cout << "The cube-layout for the solution:" << std::endl << std::endl;
static auto print = [](const std::string &cube, decltype(cube1sides) &sides) {
std::cout << cube << ": "
<< " front: " << std::setw(15) << sidetype_str(sides[0]) << ", "
<< " up: " << std::setw(15) << sidetype_str(sides[1]) << ", "
<< " top: " << std::setw(15) << sidetype_str(sides[2]) << ", "
<< " back: " << std::setw(15) << sidetype_str(sides[3])
<< std::endl;
};
print("cube #1", cube1sides);
print("cube #2", cube2sides);
print("cube #3", cube3sides);
print("cube #4", cube4sides);
}
}}}}
}
Output:
cube #1: front: php, up: phpelephant, top: phpbenelux, back: dwa cube #2: front: phpbenelux, up: dwa, top: phpelephant, back: php cube #3: front: phpelephant, up: phpbenelux, top: dwa, back: phpelephant cube #4: front: dwa, up: php, top: php, back: phpbenelux

Performance is on my pc 0,00202 seconds on average per run (see perf.txt). The average is 0,00181 seconds, 11.60% faster, if we stop processing when we find the 'first' solution.
I still think my first idea should also work and I'm curious if that "random brute-force" algorithm would on average find a solution faster compared to finding the first solution in my current solver (in terms of required compares). .
Serving specific requests from a mutable cache
You can record requests now in a new tab "Cache", and you can choose to use this cache per request. Any such request will be immediately returned from the cache (instead of being proxied).
The cool thing is that you can modify the cache, so modifying CSS / Javascript is easy for example. I wanted this feature so I can debug some stuff on environments other than development. There are other ways to do this, but I think this is very convenient.
Some use cases
- Change
<script src=...includes to URL's from production to your dev environment, to simply test javascript on production pages. - Change javascript includes to their unminified / deobfuscated versions..
- Add 'debugger' / console.log's to the source.
- I've used it to more conveniently debug www.google-analytics.com/ga.js (an obfuscated javascript), by de-obfuscating it and using the step debugger in chrome.
By the way, a cool way to set a breakpoint in Javascript on specific function calls could be this.
In ga.js there is a _gaq array, with a push function _gaq.push([something]);, I simply added this with wxhttpproxy in ga.js:
var foo = _gaq.push;
_gaq.push = function () {
debugger; <<<<< and the debugger will intercept, you can view the stacktrace
return foo.apply(_gaq, arguments);
}Features / Roadmap
Note that the wxhttpproxy will intelligently modify the Content-Length header in case you modify the content. Content-Encodings gzip/deflate are not yet supported, for the time-being the proxy will garble the Accept header (by replacing gzip -> nogz, and deflate -> noflate). This is a workaround, that makes sure gzip/deflate isn't used.
Supported for chunked encoding should be added (easy), you can already edit it manually, just remove the chunked header, the hex numbers and add a Content-Length to work around it.
Real support for gzip / deflat should be added. I already have code for gzip / deflate support laying around somewhere.
Download
As an Ubuntu/debian package available here.
- It uses wx2.8. In wx3.0 the event model has changed a bit, and I believe there is an error in the event handling w/regards to sockets. I will post some more details on this later, and if I have the time see if I can fix it..




It's really nice that at least one of my creations (phpfolding.vim) is really being picked up by others. I.e.: on Stackoverflow [1], [2], in China [1], Japan [1], [2], France [1], Holland [1], someone made a package for archlinux, creator of spf13 distribution listed as one of 15 best vim plugins. Also found a few forks on github which is really awesome, will check out if I should merge their changes back soon. These are just a few links I found now with a simple google search. This makes me regret being a little reluctant with reading my hotmail account.
I'm a bit proud it's part of the excellent spf13 vim distribution. I now use spf13 myself on my linux servers, it suprised me with some features I think are extremely smart: Like the use of numbers for each line relative to your cursor, so you can easily make X line(s) jumps or yank the correct amount of lines easily! Also the CTRL + P quick navigation that works with acronyms as well, ,, + direction key for quick jumping. And the included themes are also very nice.
To everybody that contacted me, and whom I didn't reply to from my hotmail address: please read this, I had problems with the Hotmail Junk filter *again* sorry!
This script can fold PHP functions and/or classes, properties with their PhpDoc, without manually adding marker style folds ({{{ and }}}). It will fold stuff into something like the following screenshot.

Features
- It remembers fold settings. If you add functions and execute the script again, your opened folds will not be closed.
- It will not be confused by brackets in comment blocks or string literals.
- The folding of class properties with their PhpDoc comments.
- The folding of all class properties into one fold.
- Folding the original marker style folds too.
- An "**" postfixing the fold indicates PhpDoc is inside (configurable).
- An "**#@+" postfixing the fold indicates PhpDocBlock is inside (configurable).
- Empty lines postfixing the folds can be configured to be included in the fold.
- Nested folds are supported (functions inside functions, etc.)
Future
- Better 'configurability' as opposed to editting the PHPCustomFolds() function and some "Script configuration" global variables.
Compatibility
This script is tested successfully with Vim version >= 6.3 on windows and linux (With 6.0 it works sometimes, I don't recommend using it in that version)
But I'd recommend using a new vim, at the time of writing 7.3 works fine with it!
spf13's vim distribution
You can also install spf13's vim distribution (if you like it). phpfolding.vim is included in this package too. I'm testing it out at the moment, like it so far. Kind of missed my mappings though, so I still added <F5>, <F6> and <F7> to my .vimrc.
Also I noticed EnableFastPHPFolds gives better results now better than EnablePHPFolds, this is what I experienced at work anyway, with vim 7.3. This used to be the other way around..
INSTALL
- Put phpfolding.vim in your plugin directory (~/.vim/plugin)
i.e., wget: http://www.vim.org/scripts/script.php?script_id=1623 - You might want to add the following keyboard mappings to your .vimrc:
map <F5> <Esc>:EnableFastPHPFolds<Cr> map <F6> <Esc>:EnablePHPFolds<Cr> map <F7> <Esc>:DisablePHPFolds<Cr>
- You might want to add the following lines to php.vim in your after/ftplugin
directory (~/.vim/after/ftplugin/php.vim), this will be executed after
opening a .php file:
" Don't use the PHP syntax folding setlocal foldmethod=manual " Turn on PHP fast folds EnableFastPHPFolds
- It might be necessary that you load the plugin from your .vimrc, i.e.:
let php_folding=0 (if you can't use the after directory in step 3) source ~/path/to/phpfolding.vim (if you're not using the default plugin directory)
Known issues
- C++ style commented brackets can still interfere with the bracket matching.
For example comments like are not recognized as comments: // old: for (...) {
Whereas C-style comments are, e.g.: /* old: for (...) { */ - The following won't be matched with the Regex in FindFoldStart():
function (...,
....,
....,
) {
Though Steve McConnell (writer of Code Complete) would ask why you'd need more then two lines for function parameters :)
Note: My Hotmail Junk filter probably ate a some e-mails I received from vim.org
I use my hotmail address for accounts where my e-mail is publicaly displayed, like in my profile page on vim.org. (I don't want spam in my primary e-mail inbox). So I only check my e-mail this hotmail address every now and then, probably every 6 months and it's full of stuff spam so I could have easily missed e-mails regarding phpfolding. I discovered in 2010 that there was feedback in my Junk filter, so I turned the Junk filter off, anyways that's how I remember it (and how I wrote it down). Now in 2012 I check the Junk filter again, and there is another email. Junk is automatically deleted after X days, so who knows how many mails I might have missed.
Really don't understand why it got into Junk, this specific person wrote hello, introduced himself, said something nice and signs off the e-mail. All in normal letter formatting, no URL's or e-mail addresses used, no images, just plain text. It was a valid gmail address, there were no weird Headers, and it was sent from gmail itself not some other smtp server...
You can contact me here by commenting, or send me an e-mail to the new one I use in my profile at vim.org.
I have an unfinished project with--in general--some really horrible sourcecode, but with some cool functions and solutions I came up with as well. One thing I needed for example was to calculate latitude and longitude coordinates from X and Y positions on a google maps canvas, taking zoom level into account. I could not find these conversion functions (around august 2011 anyway).
[Edit, now since May 21, 2015 Google Maps Api V3 was released, which makes it possible with the Google API. I also found an example gist here]
Aligning markers to a grid
The reason I needed these convertion functions in the first place was for creating an align feature for (custom) markers on a google maps canvas. This is how it works before/after aligning:
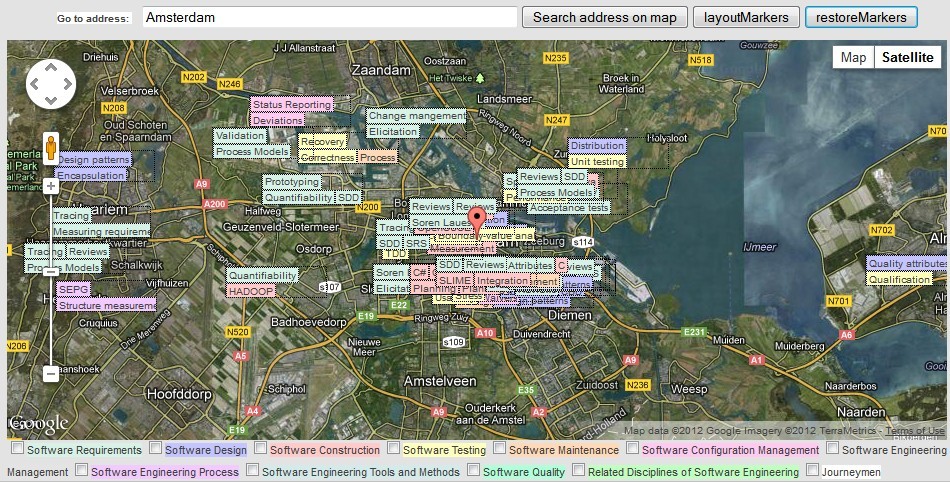
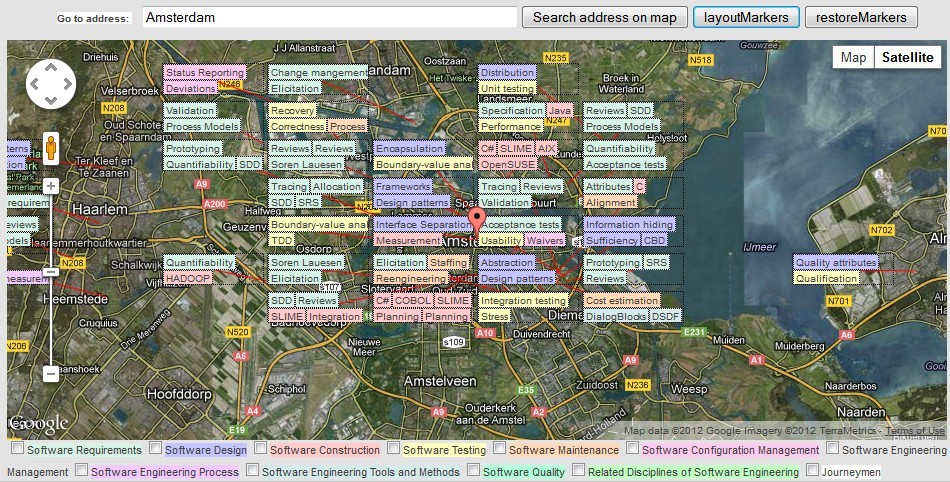
The (very simple) algorithm I came up with divides the map in slots. A grid with a width of 100 for example, only positions markers on 100, 200, 300, 400 pixels. In this example, the 'nearest' slot's width of a marker at position 220,50 pixels wouuld be 200.
The algorithm in pseudocode:
INITIALIZE GRID HEIGHT AND WIDTH ACCORDING TO MAP'S ZOOMLEVEL
/* gridwidth = 100 << (21 - map.getZoom()) */
/* gridheight = 30 << (21 - map.getZoom()) */
FOREACH MARKER
CONVERT MARKER LAT,LON TO X,Y COORDINATES
/* y = latToY(marker.getPosition().lat()); */
/* x = lonToX(marker.getPosition().lng()); */
CONVERT X,Y TO NEAREST SLOT X,Y
/* slot_y = Math.round(y - (y % gridheight)) */
/* slot_x = Math.round(x - (x % gridwidth)) */
SET MARKER X,Y TO SLOT X,Y
WHILE SLOT POSITION IS OCCUPIED BY ANOTHER MARKER
MOVE TO NEXT SLOT POSITION
/* Next slot position is according to a simple spiral movement [1] */
SET MARKER X,Y TO SLOT X,Y
ENDWHILE
CONVERT MARKER X,Y TO LAT,LON
/* marker.setPosition(new google.maps.LatLng(lat, lon)); */
/* marker.setPosition(new google.maps.LatLng(lat, log)); */
STORE SOMEWHERE THAT MARKER IS IN THIS SLOT POSITION
ENDFOREACH[1]: The search for next slot position is according to this pattern:
up, right, down, down, left, left, up, up, up, right, right, right, etc.
- The change of direction is continious (a spiral): {up, right, down, left, ..}
- The number of 'steps' in each direction is {1, 1, 2, 2, .... n, n}
latToX() and lonToY()
I'm not an expert in math but I was able to find some expressions online that resolved lat+lon for x+y (the other way around). I simply replaced all the constants with their values and put them in a solver to solve them for the variables I was interested in (e.g. longitude for XtoLon). I probably have the sites bookmarked somewhere but I can't find them.
var glOffset = 268435456;
var glRadius = 85445659.4471;// offset / pi
function lonToX(lon)
{
var p = Math.PI / 180;
var b = glRadius * lon;
var c = b * p;
return Math.round(glOffset + c);
}
function XtoLon(x)
{
return -180 + 0.0000006705522537 * x;
}
function latToY(lat)
{
return Math.round(glOffset - glRadius *
Math.log((1 + Math.sin(lat * Math.PI / 180)) /
(1 - Math.sin(lat * Math.PI / 180))) / 2);
}
function YtoLat(y)
{
var e = 2.7182818284590452353602875;
var a = 268435456;
var b = 85445659.4471;
var c = 0.017453292519943;
return Math.asin(Math.pow(e,(2*a/b-2*y/b))/(Math.pow(e,(2*a/b-2*y/b))+1)-1/(Math.pow(e,(2*a/b-2*y/b))+1))/c;
}
They are not pretty but I like them because they work really well
Edit 10-AUG-2015: deltaLonPerDeltaX(), deltaLatPerDeltaY()
I found out somebody on Stackoverflow elaborated my functions with a deltaLonPerDeltaX() and deltaLatPerDeltaY(). The original poster's image is no longer available, so I'm not sure if I understand the question correctly, and therefore these additional functions. But there is a nice extra info cited from Google, which I will copy here:
At zoom level 1, the map consists of 4 256x256 pixels tiles, resulting in a pixel space from 512x512. At zoom level 19, each x and y pixel on the map can be referenced using a value between 0 and 256 * 2^19(See [https://developers.google.com/maps/documentation/javascript/maptypes?hl=en#MapCoordinates][https://developers.google.com/maps/documentation/javascript/maptypes?hl=en#MapCoordinates])
Just wanted to use the 'in practice' part because it sounds so cool .
At work I used to have some cool tricks I'd use at customers (test-environments) or local setups to debug. One of my favourite snippets I use all the time is the following.
Record and re-create requests..
/**
* Debug helper function for logging and restoring requests. Do not use in
* production environments.
*
* - Logs the URL and request data.
* - With __STATE_DEBUGGER__ parameter in the URL it displays a listing
* of logged requests.
* - Clicking an item in that listing, re-creates that request.
*
* I know it is usually not good practice to have *one* function do multiple
* things. Make sure you know what you're doing ;)
*
* @param writableDirectory directory for saving the requests in files
* @return void (call it solely for it's side-effects ;-))
*/
function statedebugger($writableDirectory = '/tmp')
{
if (!is_dir($writableDirectory) || !is_writable($writableDirectory)) {
trigger_error('parameter writableDirectory needs to exist and be
writable', E_USER_ERROR);
}
$indexFile = $writableDirectory . '/index.txt';
if (!isset($_GET['__STATE_DEBUGGER__'])) {
// Write state file for request
$stateFileName = tempnam($writableDirectory, 'p');
$fd = fopen($stateFileName, 'wb');
fwrite($fd, serialize(array($_SERVER, $_GET, $_POST, $_REQUEST,
!isset($_SESSION) ? array() : $_SESSION)));
fclose($fd);
// Rewrite index
$indexFileContents = file_exists($indexFile) ?
file_get_contents($indexFile) : '';
$fd = fopen($indexFile, 'wb');
fwrite($fd, implode(array($indexFileContents, //INEFFICIENT
$stateFileName, ' ', $_SERVER['REQUEST_URI'], "\n")));
fclose($fd);
} else {
if (!isset($_GET['set_state'])) {
// Show index/listing of states
$indexFileLines = array_reverse(explode("\n",
file_get_contents($indexFile)));
foreach ($indexFileLines as $line) {
if (empty($line))
continue;
list($filename, $requestUri) = explode(" ", $line);
printf("<a href=\"%s%s__STATE_DEBUGGER__&set_state=%s\">%s</a><br/>\n",
$requestUri, (strpos($requestUri, "?") === FALSE ? "?" :
"&"), $filename, $requestUri);
}
exit(0);
} else {
// Restore a specific state
list ($_SERVER, $_GET, $_POST, $_REQUEST, $_SESSION) =
unserialize(file_get_contents($_GET['set_state'])); //DANGEROUS
}
}
}
statedebugger('E:/TPSC/htdocs/CRMS-Test/webframe/templates_c/');
Just paste that in the config, or whatever global headerfile (your software probably has), and it logs all requests to some specified directory. Usually when something goes wrong within a very specific context (a specific user with rights, session variables, page, ..), it would be nice to just log the requests (e.g. with post data), and use that information to re-create the (failing) request. So you can keep pressing F5 in your browser window while fixing the bug. This function does that. Also this can be especially useful when debugging AJAX requests, i.e. without firebug, or you can let the user create the very specific context (with privileges and user settings) that causes some failure, and in that way create the test-case.
(Add __STATE_DEBUGGER__ to the URL as a parameter, and it will show a listing with clickable requests.
Clicking redirects to that page and initializes it with the recorded $_GET, $_POST, $_SESSION, ...)
(By the way I didn't bother to make this very secure (see file_get_contents($_GET['set_state']) for example), because this should only be used when debugging. This could easily be improved with some numerical parameters, optional descriptions, limit to fixed number of requests...)

Topics:
Other interests:
EBPF Flamegraphs C++ Ubuntu 20.04
Site generated using ![]() ArticleManager © 2010-2013
ArticleManager © 2010-2013
