Neither one nor Many
Software engineering blog about my projects, geometry, visualization and music.
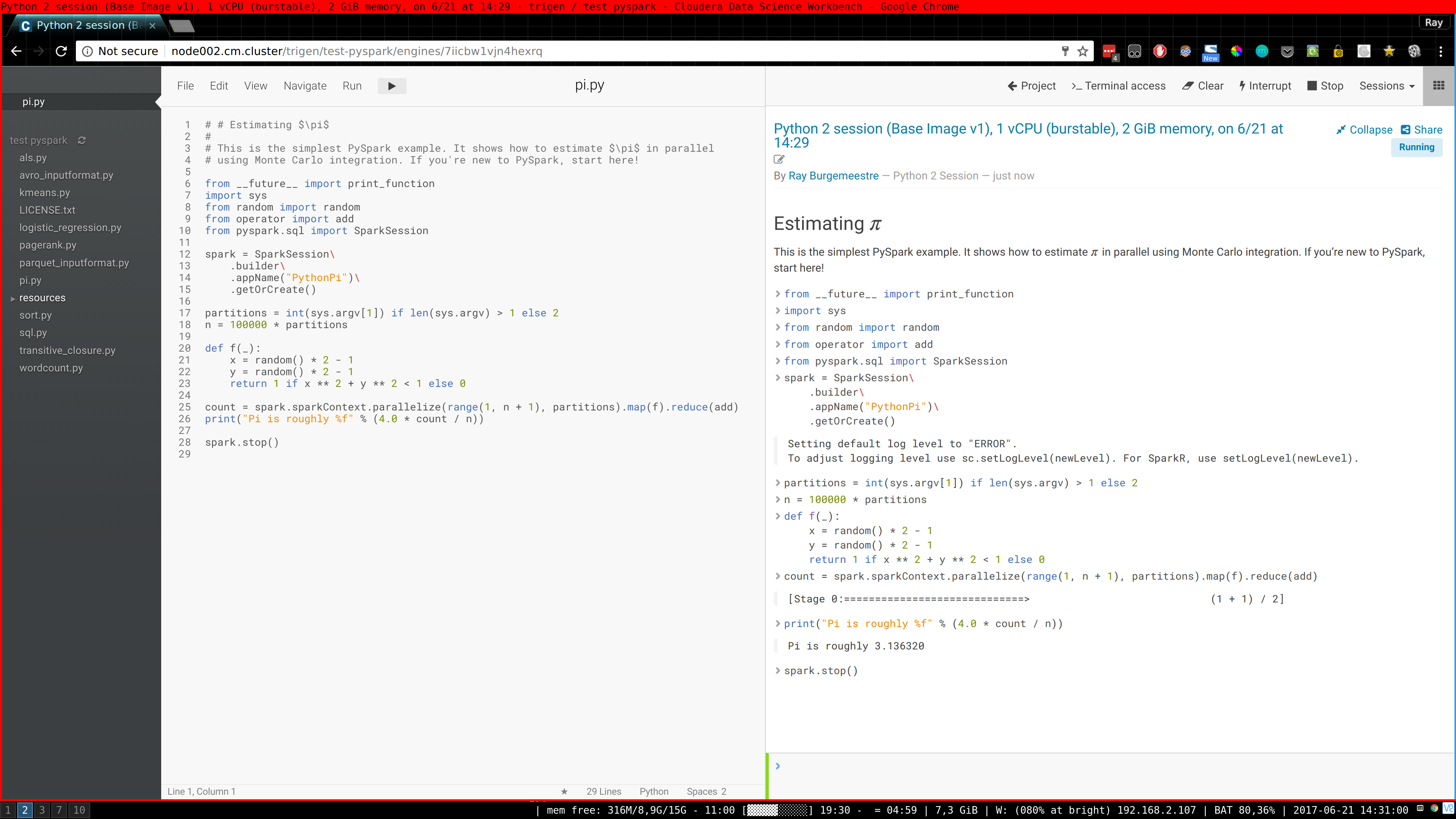
Not really a "proper" blog post but maybe useful to someone, it's basically the notes I took for myself after a few attempts to properly deploy it. It's easy to do some steps wrong if you are not super familiar with Cloudera Manager (CM).
I am not going into detail with every caveat, but https://www.cloudera.com/documentation/data-science-workbench/latest/topics/cdsw_install.html is what I used as a basis for installing Cloudera Data Science Workbench (CDSW) on top of CM.
- Do not try to deploy CM + CDSW inside Docker, because CDSW will run Kubernetes and docker inside docker AFAIK is not possible.
- Install CDSW on a computenode not the Headnode (where you deploy CM) because it needs the gateway role for finding Spark 2, etc.
In my case I am using OpenStack nodes with the following layout:
Headnode master.cm.cluster, Computenodes node00[1-6].cm.cluster (10.141.0.0/24) (. All with 8GiB Memory and 4VCPU's and 80GiB disks.
Note that you have to assign two additional volumes of 500 GiB to one of the computenodes.
I created two 200 GiB volumes (it will only give a warning that it's probably not enough, but for demo purposes it is.) and assigned them to node002.cm.cluster where I will deploy CDSW.
Versions used
- Cloudera Manager 5.11.0
- Cloudera Data Science Workbench 1.0.1.
Supported OS currently is CentOS 7.2 (apparently CDSW does not support 7.3)
Make sure port 7180 will be reachable on your Headnode so you can configure Cloudera Manager later.
Step 1: Install Cloudera Manager
Easiest for me is to just copy & paste the commands I prepared for the Docker image. First Headnode then do the same on the Compute nodes.
- Headnode - Dockerfile on Bitbucket
- Computenodes - Dockerfile on Bitbucket
If you use something like Bright Cluster Manager you probably just do the computenode stuff once in the desired computenode image and start an image transfer.
Step 2: Follow the Cloudera Manager Wizard
I install the free version and I don't install Spark, because version 1.6.0 is not supported by CDSW. You can uninstall it and replace it later if you already deployed it.
I am not going to write out every detail, but you need to install:
- The Anaconda Parcel - Link to Cloudera Blog
- The Spark 2 Parcel - Link to Cloudera Documentation
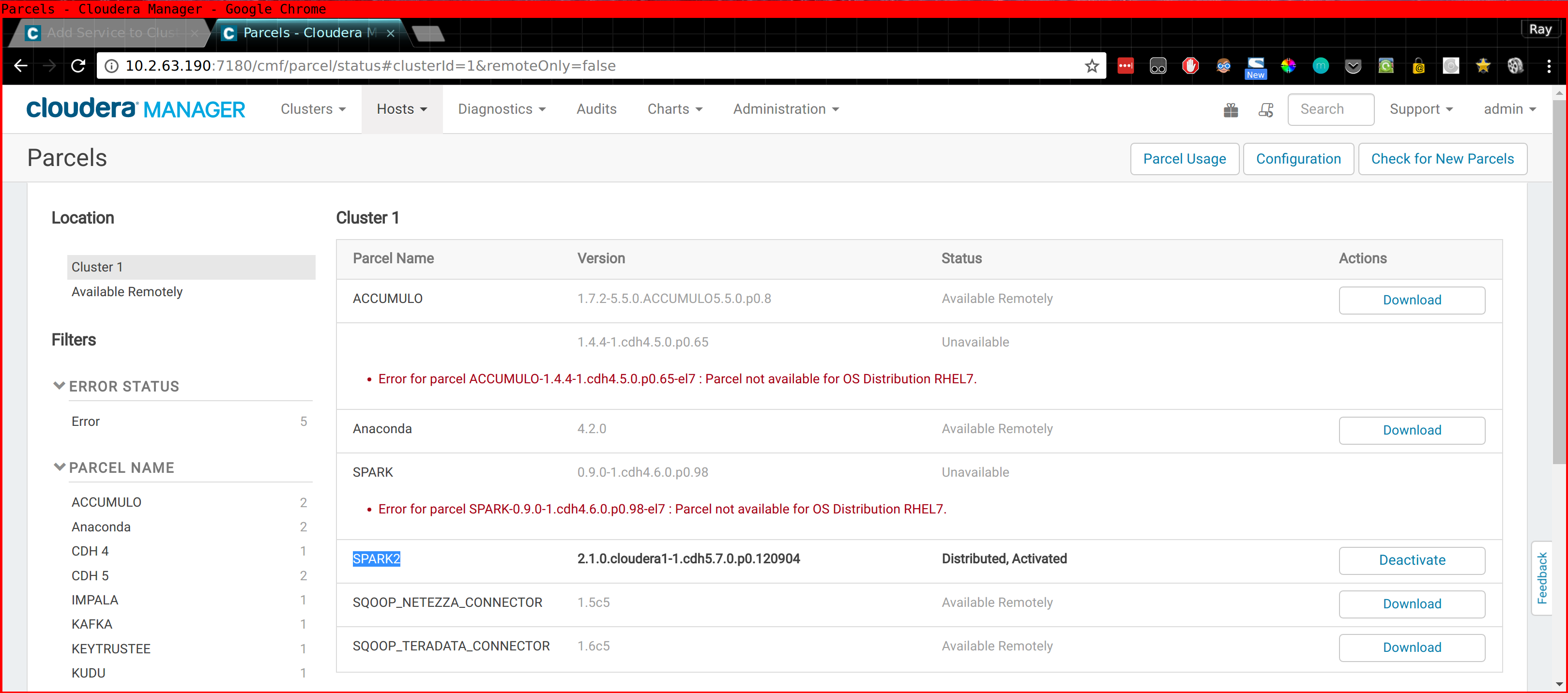
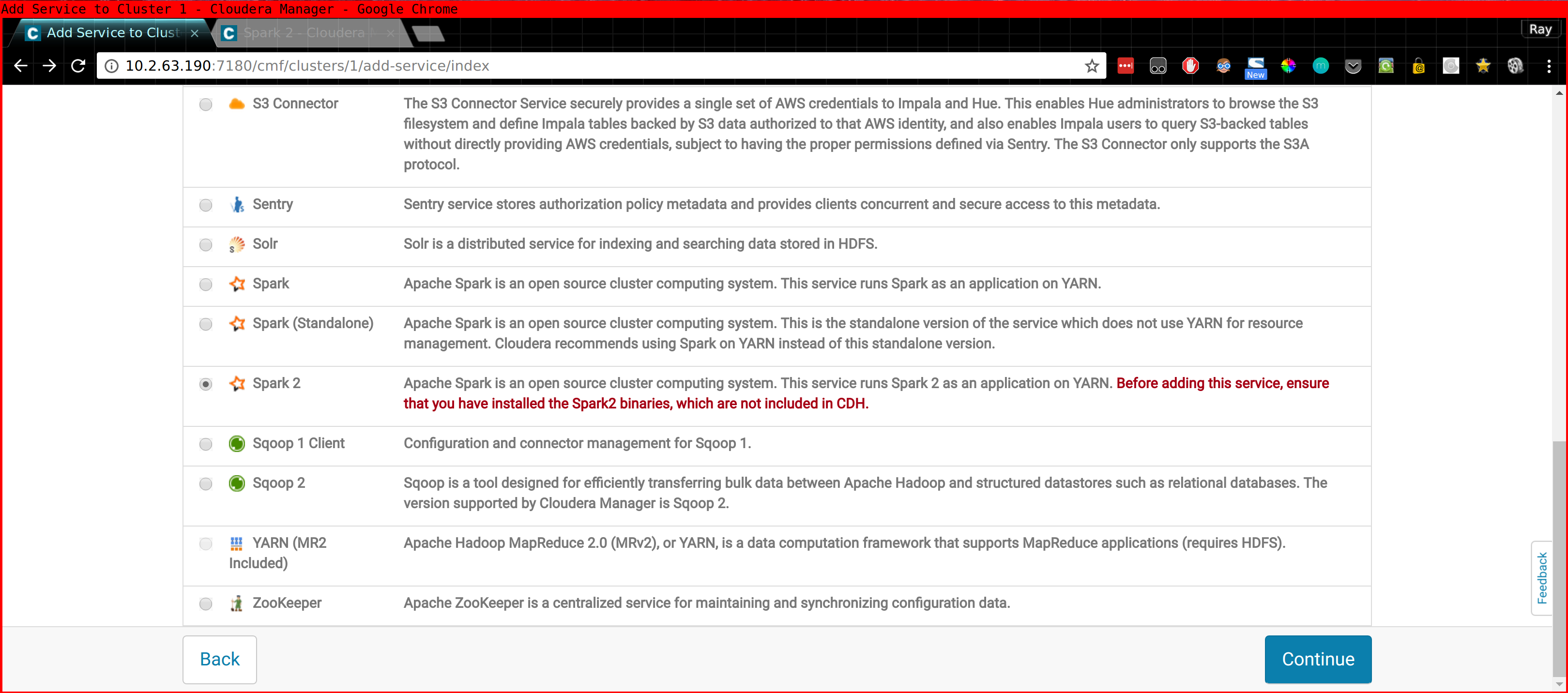
Please note that in the case of Spark 2 you also need to install the CSD (Custom Service Definition!) Or you won't find "Spark 2" when you do "Add new Service" inside CM. This stuff is described in the above links.
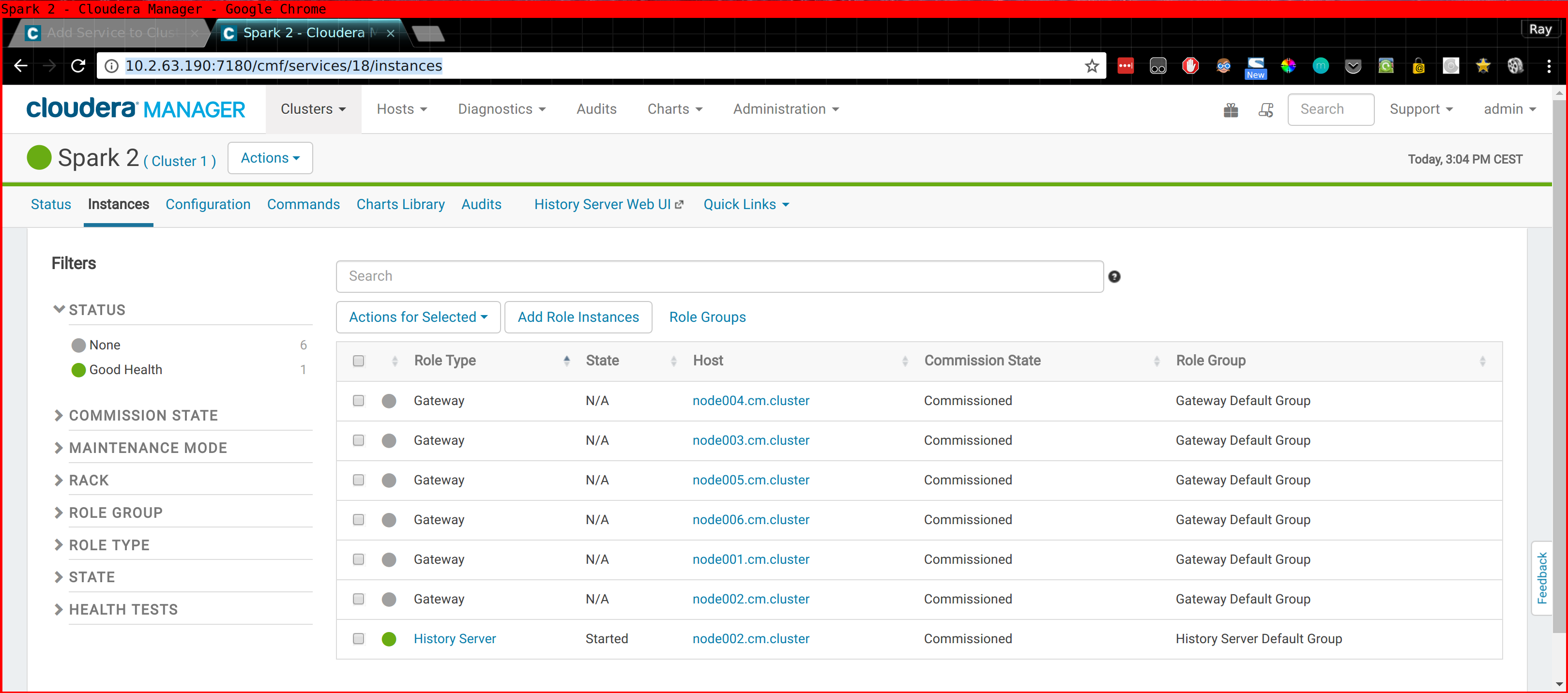
It is important that the Spark2 gateway role is assigned to the computenode where you intend to run CDSW.
Step 3: Install CDSW
Now that you have spark2-submit hopefully working on your node002.cm.cluster node, you can start to deploy CDSW there.
Write down where the additional 200GiB volumes are, something like /dev/vdc and /dev/vdd for example.
Simply yum localinstall /path/to/cloudera-data-science-workbench-1.0.1-1.el7.centos.x86_64.rpm and follow the instructions.
It should print out details on how to proceed (and you have to click OK on a lot of warnings probably)
The instructions include editing the cdsw.conf*
Which should be easy:
[root@node002 ~]# grep = /etc/cdsw/config/cdsw.conf
DOMAIN="node002.cm.cluster"
MASTER_IP="10.141.0.2"
DOCKER_BLOCK_DEVICES="/dev/vdd"
APPLICATION_BLOCK_DEVICE="/dev/vdc"
TLS_ENABLE=""
# You must also set TLS_ENABLE=true above to enable and enforce termination.
TLS_CERT=""
TLS_KEY=""
HTTP_PROXY=""
HTTPS_PROXY=""
ALL_PROXY=""
NO_PROXY=""
KUBE_TOKEN=05023c.3a168925213858dcIf a previous cdsw init failed, just run cdsw reset first.
One of the steps that failed during cdsw init in my case was docker, I edited the Docker service file (systemctl status docker to find the location)
I removed the --storage parameters from /etc/systemd/system/docker.service:
ExecStart=/usr/bin/docker daemon \
--log-driver=journald \
-s devicemapper \
--storage-opt dm.basesize=100G \
--storage-opt dm.thinpooldev=/dev/mapper/docker-thinpool \
--storage-opt dm.use_deferred_removal=true \
--iptables=falseLeaving:
ExecStart=/usr/bin/docker daemon \
--log-driver=journald \
-s devicemapper \
--iptables=falseBefore running cdsw init.
Please write down the kubeadm join command that is suggested, and have fun waiting for watch cdsw status.
- Make sure you create a user in HDFS (i.e., su hdfs, hdfs dfs ... on one of the computenodes)
Adding extra nodes to the CDSW Kubernetes cluster
Forgot to write details down for this, but I think you can just yum localinstall the cdsw rpm first for all dependencies like docker, kubernetes. Then there is the following command you can execute:
kubeadm join --token=05023c.3a168925213858dc 10.141.0.2This was printed earlier when we ran cdsw init on node002.
Test setup
In my case I did not really properly configure DNS etc., it's just a test setup. So I needed to add the following to my hosts file and add some of the more important hosts:
10.141.0.2 node002 node002.cm.cluster livelog.node002.cm.cluster consoles.node002.cm.cluster(For console access some random hostname is used, you may have to add those in case you stumble upon a non resolving hostname..)
You might need to start a tunnel to the cluster if your computenodes are not exposed like this:
function tun {
sshuttle -r root@$1 10.141.0.0/16
}
tun <IP>

Topics:
Other interests:
EBPF Flamegraphs C++ Ubuntu 20.04
Site generated using ![]() ArticleManager © 2010-2013
ArticleManager © 2010-2013

Teknik Telekomunikasi
website: https://smb.telkomuniversity.ac.id/ @
2024-07-02 13:36:51