Neither one nor Many
Software engineering blog about my projects, geometry, visualization and music.
Just to announce I created a new version that supports a non-GUI interface. This makes installing and running it commandline on a linux server easy.
CLI interface
ksh$ wxhttpproxy --help
Usage: wxhttpproxy [-h] [-f <str>] [-n <num>] [-p <num>] [-q]
-h, --help displays help on the command line parameters.
-f, --file=<str> output everything to <file>.
-n, --number=<num> truncate file each <num> lines (default 500000).
-p, --port=<num> bind to port <port> (default 8888).
-q, --quiet silent output (nothing to stdout).Building
trigen@Rays-MacBook-Pro.local:/tmp> git clone git@bitbucket.org:rayburgemeestre/wxhttpproxy.git
Cloning into 'wxhttpproxy'...
remote: Counting objects: 394, done.
remote: Compressing objects: 100% (391/391), done.
remote: Total 394 (delta 269), reused 0 (delta 0)
Receiving objects: 100% (394/394), 1.04 MiB | 225.00 KiB/s, done.
Resolving deltas: 100% (269/269), done.
Checking connectivity... done.
trigen@Rays-MacBook-Pro.local:/tmp> cd wxhttpproxy/
/tmp/wxhttpproxy
trigen@Rays-MacBook-Pro.local:/tmp/wxhttpproxy[master]> cmake .
-- The C compiler identification is AppleClang 6.0.0.6000056
-- The CXX compiler identification is AppleClang 6.0.0.6000056
-- Check for working C compiler: /usr/bin/cc
-- Check for working C compiler: /usr/bin/cc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/c++
-- Check for working CXX compiler: /usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Found wxWidgets: TRUE
/usr/local/Cellar/cmake/3.0.2/share/cmake/Modules/UsewxWidgets.cmake
-- Configuring done
-- Generating done
-- Build files have been written to: /tmp/wxhttpproxy
trigen@Rays-MacBook-Pro.local:/tmp/wxhttpproxy[master]> make
Scanning dependencies of target wxhttpproxy
[ 10%] Building CXX object CMakeFiles/wxhttpproxy.dir/src/application.cpp.o
[ 20%] Building CXX object CMakeFiles/wxhttpproxy.dir/src/cache.cpp.o
[ 30%] Building CXX object CMakeFiles/wxhttpproxy.dir/src/clientdata.cpp.o
[ 40%] Building CXX object CMakeFiles/wxhttpproxy.dir/src/consoleoutputhandler.cpp.o
[ 50%] Building CXX object CMakeFiles/wxhttpproxy.dir/src/guioutputhandler.cpp.o
[ 60%] Building CXX object CMakeFiles/wxhttpproxy.dir/src/httpbuffer.cpp.o
[ 70%] Building CXX object CMakeFiles/wxhttpproxy.dir/src/httpproxywindow.cpp.o
[ 80%] Building CXX object CMakeFiles/wxhttpproxy.dir/src/logger.cpp.o
[ 90%] Building CXX object CMakeFiles/wxhttpproxy.dir/src/socketbuffer.cpp.o
[100%] Building CXX object CMakeFiles/wxhttpproxy.dir/src/socketserver.cpp.o
Linking CXX executable wxhttpproxy
[100%] Built target wxhttpproxy
trigen@Rays-MacBook-Pro.local:/tmp/wxhttpproxy[master]>Changelog
Version 1.2: ![]()
- Proper Connection: keep-alive support (with reconnects when necessary)
- Support switching to different hosts/backends within a connection.
- Commandline (Non-GUI) version, with logging+truncate feature.
- An actual 1337 icon for the program!
Version 1.1:
- HTTPS support
- OSX support
- Stability fixes
- Support for caching content and serving from cache.
Version 1.0:
- HTTP proxy that supports CONNECT and GET syntax.
CLI example usage (http_proxy=http://localhost:8888 curl http://cppse.nl/test.txt)
ksh$ wxhttpproxy
Info - Server listening on port 8888.
Thread #1 - New client connection accepted
Thread #1 - Connecting to host cppse.nl:80 for client.
Thread #1 - Request from client: GET /test.txt HTTP/1.1
Thread #1 - Host socket connected.
Thread #1 - >>>: GET /test.txt HTTP/1.1
Thread #1 - >>>: User-Agent: curl/7.30.0
Thread #1 - >>>: Host: cppse.nl
Thread #1 - >>>: Accept: */*
Thread #1 - >>>: Proxy-Connection: Keep-Alive
Thread #1 - >>>:
Thread #1 - Response from host.
Thread #1 - <<<: HTTP/1.1 200 OK
Thread #1 - <<<: Date: Sun, 28 Dec 2014 21:05:09 GMT
Thread #1 - <<<: Server: Apache/2.4.6 (Ubuntu)
Thread #1 - <<<: Last-Modified: Sun, 09 Feb 2014 00:48:33 GMT
Thread #1 - <<<: ETag: "c-4f1ee951f920c"
Thread #1 - <<<: Accept-Ranges: bytes
Thread #1 - <<<: Content-Length: 12
Thread #1 - <<<: Connection: close
Thread #1 - <<<: Content-Type: text/plain
Thread #1 - <<<:
Thread #1 - <<<: Hello world
Thread #1 - Host socket disconnected.
The problem
The title being a reference to this article from 2011, a blog post from someone who encountered a similar issue once ![]() . Hopefully my blog post will prevent someone else from spending a day on this issue. We are in the middle of a migration from Oracle 11.2 to 12.1, and from PHP, Zend server more specifically, we had some connectivity problems to Oracle, the PHP function oci_connect() returned:
. Hopefully my blog post will prevent someone else from spending a day on this issue. We are in the middle of a migration from Oracle 11.2 to 12.1, and from PHP, Zend server more specifically, we had some connectivity problems to Oracle, the PHP function oci_connect() returned:
PHP Warning: oci_connect(): ORA-28547: connection to server failed, probable Oracle Net admin error in /home/webro/test.php on line 2Good luck googleing that Oracle error code, nothing hints in the right direction, only that it's an error that occurs after the connection is established. Quote from http://ora-28547.ora-code.com/:
A failure occurred during initialization of a network connection from a client process to the Oracle server: The connection was completed but a disconnect occurred while trying to perform protocol-specific initialization, usually due to use of different network protocols by opposite sides of the connection.
The problem in our case was with the characterset
The "tl;dr" is: you may be using an Oracle "Light" client instead of the "Basic" client. In Zend Server this means that in the Zend Server lib path some libraries are missing. The Light client only supports a few charactersets. If you have some other Characterset that isn't default, that may be the problem. You need to make sure the Oracle Instant client Zend Server is using is the Basic client.
Unfortunately you cannot tell this from the phpinfo() output. Both Light and Basic return exactly the same version information.
Oracle Run-time Client Library Version => 11.2.0.2.0
Oracle Instant Client Version => 11.2How we found out..
Luckily I was able to succesfully connect from another virtual machine to the new database server. This was an older Zend server instance, where the Oracle instant client was patched from 11.1 to 11.2. The Zend server that failed had 11.2, so we assumed patching wasn't necessary. I compared the strace outputs.
The first observation was that during the communication the server--on the right in the following image--stopped and concludes there is a communication error.
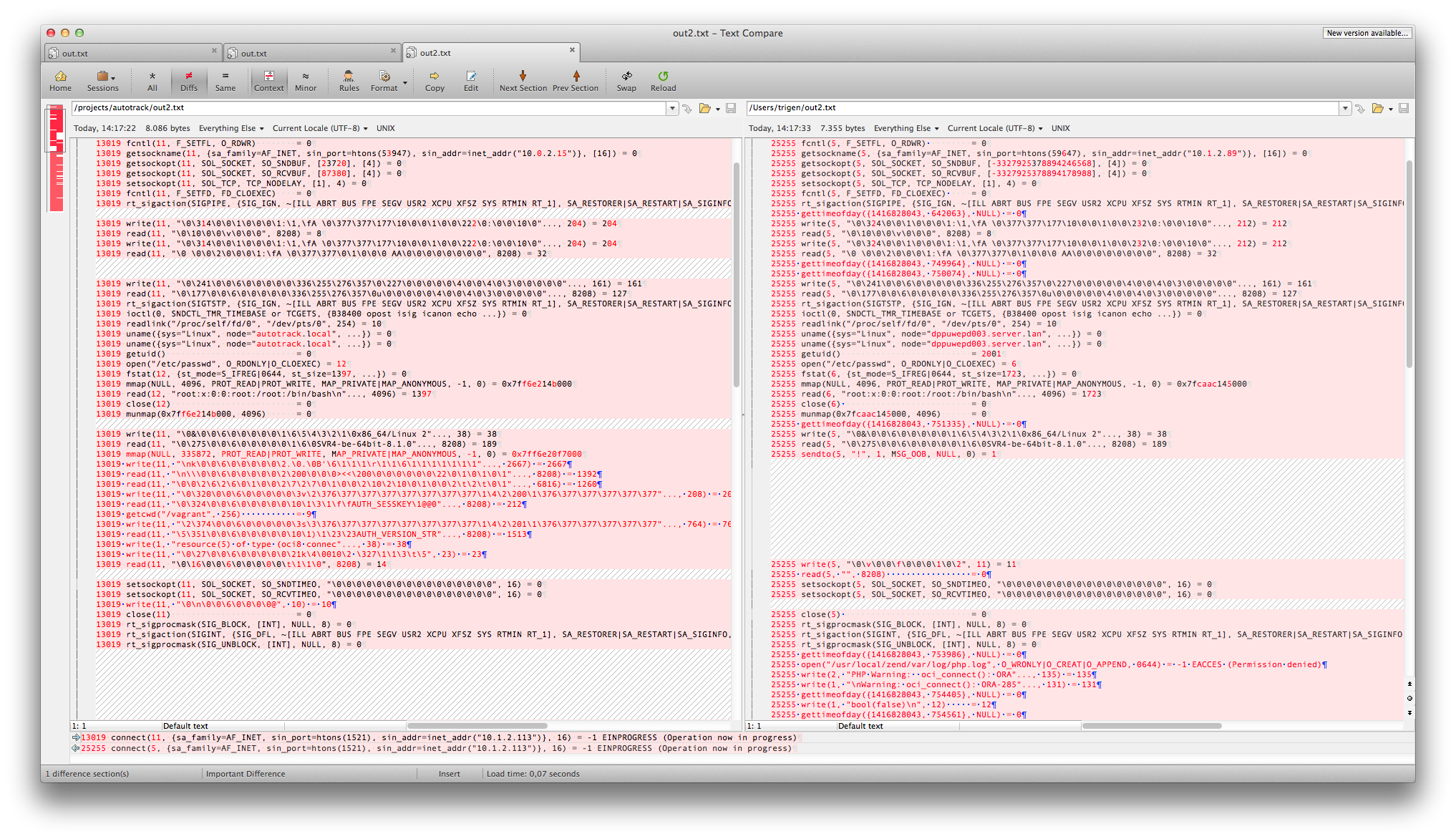
Working VM on the left, failing server on the right.
The second observation in the diff was that there was also a difference between libraries loaded.
- 9166 open("/usr/local/zend/lib/libociei.so", O_RDONLY) = -1 ENOENT (No such file or directory)
- 9166 open("/usr/local/zend/lib/libociicus.so", O_RDONLY) = 4
+ 17606 open("/usr/local/zend/lib/libociei.so", O_RDONLY) = 4More insight into the problem..
We didn't specify explicitly what characterset to use for the connection, so it will try to find out after the connection is established. We use WE8ISO8859P15 in our database, and that charset is (amongst others) provided by libociei.
$ strings /usr/lib/oracle/11.2/client64/lib/libociei.so|grep WE8ISO8859P15
WE8ISO8859P15
...Had we specified the charset in the oci_connect parameter (fourth param) we would have seen:
PHP Warning: oci_connect(): OCIEnvNlsCreate() failed. There is something wrong with your system - please check that LD_LIBRARY_PATH includes the directory with Oracle Instant Client libraries in /home/webro/test.php on line 4
PHP Warning: oci_connect(): ORA-12715: invalid character set specified in /home/webro/test.php on line 4That would have hinted us to the solution earlier. Also in strace there would have been no connection setup at all, as the client can now bail sooner with "Invalid character set specified". Apparently with the Light oracle client version 11.1 the error used to be more helpful (see beforementioned blog post here):
ORA-12737: Instant Client Light: unsupported server character set WE8ISO8859P15The fix for Zend server
Replace the Light client with the Basic client, in our case this meant adding a library to Zend Server's libs:
# After installing the oracle instant client BASIC
ln -s /usr/lib/oracle/11.2/client64/lib/libociei.so /usr/local/zend/lib/libociei.soApparently the difference between Light & Basic is just this one library. The package that provides the Basic client may differ per Linux distribution, you can also download it from oracle.com.
In Jira's Agile Board the Ranks of the Issues are visualized underneath the Story point estimates. The highest rank is colored green, the lower the priority becomes, the more the color changes to red. This way it also becomes visible who is not working according to priorities. See the following screenshot.
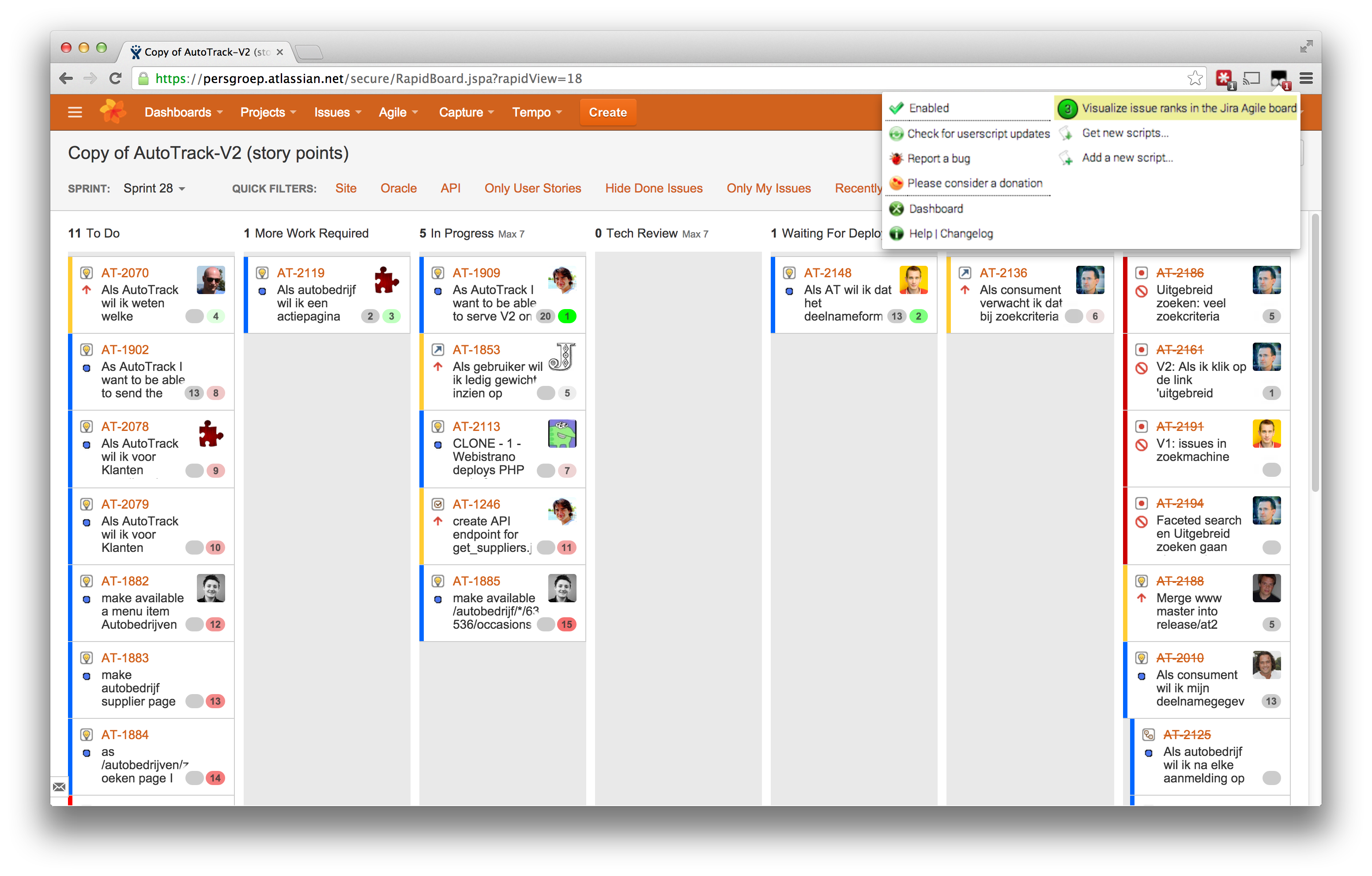
King - Servant pattern
At work we use the King-Servant pattern (see screenshot I made of slide 47 from this pdf) to avoid too much concurrent work. This pattern tries to solve the problem that you could end up with four unfinished tickets rather than two or even one complete ticket(s).

We work with remote programmers and therefore don't use a physical Scrum board.
During the day and standups we view this board often and found it annoying that
in order to determine the "King" ticket, you would need to switch back and
forth the "Plan mode" a lot to see the Ranks. The different swimlanes often
obfuscate the ranking information.
With this script the king ticket is simply the one with rank "1". ")
The tampermonkey / greasemonkey script to give you this precious feature
Editing configuration may be required to adjust it to your board.
- You can view/copy/download it from my gist at github and click the
Rawbutton and copy & paste.
- Chrome: You can use the Tampermonkey extension, "add new script", copy & paste the script and save.
- FireFox: You can use the Greasemonkey add-on, add user script, and you need to explicitly add
http*://*.atlassian.net/secure/RapidBoard.jspa?*as an include url, then copy & paste the script code from clipboard and save. Sorry Greasemonkey is not very user friendly.
[Edit 2-Nov-2014, I've changed my mind with the coloring, and some other things. The original version 1 is still available here]
[Edit 2-Jun-2015, I actually use the following script URL: //cppse.nl/public/tampermonkey_agile_board_prios.js and keep it up-to-date with my gist]
Problem
The symptom is that while editing the IDE freezes, somehow the keyboard no
longer responds. Two years ago at Tweakers there was luckily someone using
Ubuntu who could tell me right away how to fix it ("Just killall -9
ibus-x11", and it would magically continue to work). Now more recently at
AutoTrack--where I now work--a collegue encountered the same issue. Luckily I
knew the fix this time. ![]()
The fact that I personally know at least five different individuals who spent time fixing this makes me guess there are a lot more people still. Hence this blogpost with some keywords that will hopefully lure others into this fix...
Fix
According to this bug report:
killall -HUP ibus-daemonOr use this one:
killall -9 ibus-x11
I have no idea what ibus exactly is, and I don't really care ![]() Also it may be possible to just uninstall ibus, I didn't try this,
but I can imagine the following to work..
Also it may be possible to just uninstall ibus, I didn't try this,
but I can imagine the following to work..
sudo apt-get remove ibusDeflate and Gzip compress and decompress functions
When implementing a gzip compression & decompression for my blog. I stumbled upon two C++ functions by Timo Bingmann:
- string : compress_string(string)
- string : decompress_string(string)
Renamed these and created two gzip versions from them:
- string : compress_deflate(string)
- string : decompress_deflate(string)
- string : compress_gzip(string)
- string : decompress_gzip(string)
These are the differences:

Complete source
#include <string>
#include <sstream>
#include <stdexcept>
#include <string.h>
#include "zlib.h"
using std::string;
using std::stringstream;
// Found these here http://mail-archives.apache.org/mod_mbox/trafficserver-dev/201110.mbox/%3CCACJPjhYf=+br1W39vyazP=ix
//eQZ-4Gh9-U6TtiEdReG3S4ZZng@mail.gmail.com%3E
#define MOD_GZIP_ZLIB_WINDOWSIZE 15
#define MOD_GZIP_ZLIB_CFACTOR 9
#define MOD_GZIP_ZLIB_BSIZE 8096
// Found this one here: http://panthema.net/2007/0328-ZLibString.html, author is Timo Bingmann
// edited version
/** Compress a STL string using zlib with given compression level and return
* the binary data. */
std::string compress_gzip(const std::string& str,
int compressionlevel = Z_BEST_COMPRESSION)
{
z_stream zs; // z_stream is zlib's control structure
memset(&zs, 0, sizeof(zs));
if (deflateInit2(&zs,
compressionlevel,
Z_DEFLATED,
MOD_GZIP_ZLIB_WINDOWSIZE + 16,
MOD_GZIP_ZLIB_CFACTOR,
Z_DEFAULT_STRATEGY) != Z_OK
) {
throw(std::runtime_error("deflateInit2 failed while compressing."));
}
zs.next_in = (Bytef*)str.data();
zs.avail_in = str.size(); // set the z_stream's input
int ret;
char outbuffer[32768];
std::string outstring;
// retrieve the compressed bytes blockwise
do {
zs.next_out = reinterpret_cast<Bytef*>(outbuffer);
zs.avail_out = sizeof(outbuffer);
ret = deflate(&zs, Z_FINISH);
if (outstring.size() < zs.total_out) {
// append the block to the output string
outstring.append(outbuffer,
zs.total_out - outstring.size());
}
} while (ret == Z_OK);
deflateEnd(&zs);
if (ret != Z_STREAM_END) { // an error occurred that was not EOF
std::ostringstream oss;
oss << "Exception during zlib compression: (" << ret << ") " << zs.msg;
throw(std::runtime_error(oss.str()));
}
return outstring;
}
// Found this one here: http://panthema.net/2007/0328-ZLibString.html, author is Timo Bingmann
/** Compress a STL string using zlib with given compression level and return
* the binary data. */
std::string compress_deflate(const std::string& str,
int compressionlevel = Z_BEST_COMPRESSION)
{
z_stream zs; // z_stream is zlib's control structure
memset(&zs, 0, sizeof(zs));
if (deflateInit(&zs, compressionlevel) != Z_OK)
throw(std::runtime_error("deflateInit failed while compressing."));
zs.next_in = (Bytef*)str.data();
zs.avail_in = str.size(); // set the z_stream's input
int ret;
char outbuffer[32768];
std::string outstring;
// retrieve the compressed bytes blockwise
do {
zs.next_out = reinterpret_cast<Bytef*>(outbuffer);
zs.avail_out = sizeof(outbuffer);
ret = deflate(&zs, Z_FINISH);
if (outstring.size() < zs.total_out) {
// append the block to the output string
outstring.append(outbuffer,
zs.total_out - outstring.size());
}
} while (ret == Z_OK);
deflateEnd(&zs);
if (ret != Z_STREAM_END) { // an error occurred that was not EOF
std::ostringstream oss;
oss << "Exception during zlib compression: (" << ret << ") " << zs.msg;
throw(std::runtime_error(oss.str()));
}
return outstring;
}
/** Decompress an STL string using zlib and return the original data. */
std::string decompress_deflate(const std::string& str)
{
z_stream zs; // z_stream is zlib's control structure
memset(&zs, 0, sizeof(zs));
if (inflateInit(&zs) != Z_OK)
throw(std::runtime_error("inflateInit failed while decompressing."));
zs.next_in = (Bytef*)str.data();
zs.avail_in = str.size();
int ret;
char outbuffer[32768];
std::string outstring;
// get the decompressed bytes blockwise using repeated calls to inflate
do {
zs.next_out = reinterpret_cast<Bytef*>(outbuffer);
zs.avail_out = sizeof(outbuffer);
ret = inflate(&zs, 0);
if (outstring.size() < zs.total_out) {
outstring.append(outbuffer,
zs.total_out - outstring.size());
}
} while (ret == Z_OK);
inflateEnd(&zs);
if (ret != Z_STREAM_END) { // an error occurred that was not EOF
std::ostringstream oss;
oss << "Exception during zlib decompression: (" << ret << ") "
<< zs.msg;
throw(std::runtime_error(oss.str()));
}
return outstring;
}
std::string decompress_gzip(const std::string& str)
{
z_stream zs; // z_stream is zlib's control structure
memset(&zs, 0, sizeof(zs));
if (inflateInit2(&zs, MOD_GZIP_ZLIB_WINDOWSIZE + 16) != Z_OK)
throw(std::runtime_error("inflateInit failed while decompressing."));
zs.next_in = (Bytef*)str.data();
zs.avail_in = str.size();
int ret;
char outbuffer[32768];
std::string outstring;
// get the decompressed bytes blockwise using repeated calls to inflate
do {
zs.next_out = reinterpret_cast<Bytef*>(outbuffer);
zs.avail_out = sizeof(outbuffer);
ret = inflate(&zs, 0);
if (outstring.size() < zs.total_out) {
outstring.append(outbuffer,
zs.total_out - outstring.size());
}
} while (ret == Z_OK);
inflateEnd(&zs);
if (ret != Z_STREAM_END) { // an error occurred that was not EOF
std::ostringstream oss;
oss << "Exception during zlib decompression: (" << ret << ") "
<< zs.msg;
throw(std::runtime_error(oss.str()));
}
return outstring;
}
// Compile: g++ -std=c++11 % -lz
// Run: ./a.out
#include <iostream>
int main()
{
std::string s = "Hello";
std::cout << "input: " << s << std::endl;
std::cout << "gzip compressed: " << compress_gzip(s) << std::endl;;
std::cout << "gzip decompressed: " << decompress_gzip(compress_gzip(s)) << std::endl;;
std::cout << "deflate compressed: " << compress_deflate(s) << std::endl;;
std::cout << "deflate decompressed: " << decompress_deflate(compress_deflate(s)) << std::endl;;
}
Compile
g++ -std=c++11 % -lz
Run
./a.out
Output

Sometimes as a webdeveloper I have to work with websites where performance is not optimal and sacrifised in exchange for some other quality attribute.
Perhaps that's why I "over optimize" some sites--like this blog--which probably is not even worth the effort considering the traffic it gets.
However, it's something I spend my time on and it could be useful to others. And this being a blog, I blog about it.
Statically compile
In this blog I statically "compile" this websit with a minimalist tool I created. It was a project with a similar approach as octopress (based on Jekyll). I've never used octopress, I'm not sure if it even existed back when starting this blog.
A webserver likes plain file serving more than CPU intensive PHP scripts (that generate pages per request). You may not need to statically compile everything like I do, there are alternatives like using Varnish cache to optimize your performance perhaps. Tweakers.net (and many more high performance websites) use Varnish.
YSlow & Page Speed diagnostiscs
These are browser plugins, but you can do the checks online via services like: GTmetrix or WebPageTest. In the following screenshot are as an example some quick wins I made using GTmetrix in two ours of optimizing my blog.
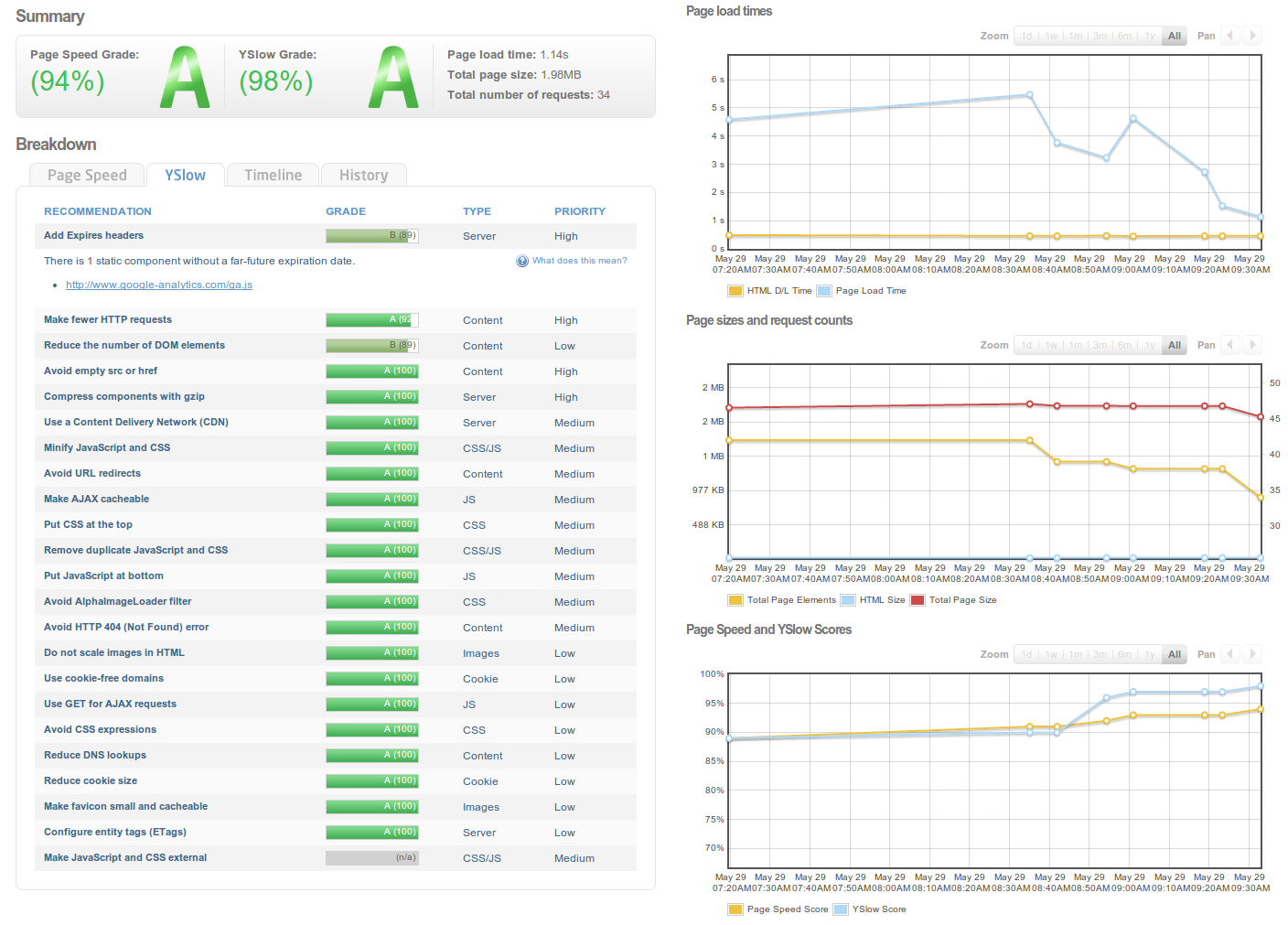
In this blog I won't go over all the Tips given on those websites, but there is a lot of useful advice in there I won't repeat. Except for maybe one more: Caching headers for clients (and (caching) proxies), you might want to make sure you get those right. ![]()
Cloudfront as a Content Delivery Network (CDN)
In google analytics I noticed that in some countries my blog was a lot slower. Especially the loading of media.
I verified this with WebPageTest, apparently my AWS server that was located in Ireland was too far away for some countries. Maybe not especially slow for the HTML, but especially for media, like images, a.k.a. "Content". Hence, CDN ![]()
First how to setup a CDN with Cloudfront...
You start with creating an "S3" bucket, which is basically a "dumb" but fast hosting for files. For every file you put there you have to set permissions, headers (if you want those headers to be returned to the client (i.e. Content-Type, etc.)). Normally a webserver like apache would do most of that stuff for you, here you have to do it yourself. All your static content should be uploaded to such a bucket.
Your bucket is something named like <BUCKETNAME>.s3-website-eu-west-1.amazonaws.com.
As you can guess from the domain name, the bucket is hosted in one location. With "one location" I mean the unique URL, but also "EU West 1", which is one region (or location).
Files in the bucket are accessible via HTTP: //cdn-cppse-nl.s3-website-eu-west-1.amazonaws.com/some/path/to/a/file.txt.
If you put Cloudfront in front of your bucket, you can make if fetch from your bucket, and "cache" it in X locations all over the world. Your cloudfront endpoint is something like <UNIQUEID>.cloudfront.net.
When you want to use another domain in your HTML, you can define a CNAME (canonical name, a hostname that resolves to another hostname basically), which is a dns record that points to the cloudfront.net domain. In my case cdn.cppse.nl points to d15zg7znhuffnz.cloudfront.net (which reads from cdn-cppse-nl.s3-website-eu-west-1.amazonaws.com).
Creating a CNAME has the advantage that you can at DNS level switch to another CDN. If I were to use akamai, I can make the CNAME point to something from akamai. I could also prepare a totally new bucket and/or cloudfront endpoint, and then switch to the new endpoint by changing the CNAME to another <UNIQUEID2>.cloudfront.net.
Second how Cloudfront / CDNs work...
Cloudfront hostname resolves to multiple IP addresses. At DNS level the actual "edge" (a.k.a. server, in terms of it's ip address) is chosen where the actual files are to be fetched from. You can interpret all the cloudfront edges as "mirrors" for your S3 bucket. On my home PC (which is currently near Amsterdam) when I resolve cdn.cppse.nl (d15zg7znhuffnz.cloudfront.net) it is resolved to a list of IP's:
> cdn.cppse.nl
Server: 127.0.1.1
Address: 127.0.1.1#53
Non-authoritative answer:
cdn.cppse.nl canonical name = d15zg7znhuffnz.cloudfront.net.
Name: d15zg7znhuffnz.cloudfront.net
Address: 54.230.13.72
Name: d15zg7znhuffnz.cloudfront.net
Address: 54.230.12.206
Name: d15zg7znhuffnz.cloudfront.net
Address: 54.230.12.246
Name: d15zg7znhuffnz.cloudfront.net
Address: 54.230.13.12
Name: d15zg7znhuffnz.cloudfront.net
Address: 54.230.13.65
Name: d15zg7znhuffnz.cloudfront.net
Address: 54.230.12.249
Name: d15zg7znhuffnz.cloudfront.net
Address: 54.230.13.2
Name: d15zg7znhuffnz.cloudfront.net
Address: 54.230.15.34The fastest "edge" for my location is returned first and has the address: 54.230.13.72.
If you reverse DNS lookup that IP you can see "ams1" in the hostname the ip resolved too.
> 54.230.13.72
Server: 127.0.1.1
Address: 127.0.1.1#53
Non-authoritative answer:
72.13.230.54.in-addr.arpa name = server-54-230-13-72.ams1.r.cloudfront.net.
Authoritative answers can be found from:
This is specific to how Amazon structures their hostnames. ams1 in server-54-230-13-72.ams1.r.cloudfront.net stands for Amsterdam Airport Schiphol. Their coding is based on the closest International Airport IATA code.
You can check how the domain resolves and what latency/packetloss is from a lot of different "checkpoints" (locations) at once, with tools like APM Cloud Monitor. In China/Hong Kong the address it resolves to is: 54.230.157.116. The reverse dns resolution for that ip is server-54-230-157-116.sin3.r.cloudfront.net, where SIN is the code for Republic of Singapore. So they won't have to download my javascript/css/media there all the way from Amsterdam.
If your website is entirely static, you could host everything this way. And hopefully people from all over the world can benefit from fast downloads from their nearest edges.
A few challenges I had with Cloudfront
After switching to Cloudfront I first noticed that loadtimes increased! ![]() I forgot that my apache used
I forgot that my apache used mod_gzip (and mod_deflate) to send text-based content compressed to the http client/webbrowser. But I uploaded my stuff to S3 "as is", which is plain/text and not gzipped.
A webbrowser normally sends in it's request whether it supports gzip or deflate encoding. If it does, apache will compress the content in a way to the client's preference, otherwise it will serve the content "as is". S3 is simply a key-value store in a way, so this conditional behaviour based on a client's headers like Accept-Encoding:gzip,deflate,sdch isn't possible. In the documentation you see that you have to create separate files.
Unfortunately Javascript doesn't have access to the browsers Accept-Encoding header (that one my chromium sends). So you cannot document.write the correct includes based on this client-side. That was my first idea.
How I now resolved it: For the CSS and Javascript files served from Cloudfront, I upload the plain version file.css and a compressed version file.gz.css. With correct headers etc., like this:
# Create expiry date
expir="$(export LC_TIME="en_US.UTF-8"; date -u +"%a, %d %b %Y %H:%M:%S GMT" --date "next Year")"
# Copy global.js to global.gz.js and gzip compress the copy
cp -prv global.js global.gz.js
gzip -9 global.gz.js
# Upload the files to bucket
s3cmd --mime-type=text/css \
--add-header="Expires:$expir" \
--add-header=Cache-Control:max-age=31536000 \
-P put global.js s3://cdn-cppse-nl/global.js
s3cmd --mime-type=text/css \
--add-header=Content-Encoding:gzip \
--add-header="Expires:$expir" \
--add-header=Cache-Control:max-age=31536000 \
-P put global.gz.js s3://cdn-cppse-nl/global.gz.jss3cmd is awesome for uploading stuff to s3 buckets. It also has a very useful sync command.
Perfect routing
Because I now have separate files for compressed and uncompressed javascript/css files, I cannot serve my static HTML files "blindly" from my CDN anymore.
I now have to make sure I send the HTML either with references to file.gz.css or file.css based on the client's browser request headers.
So I introduced "Perfect routing", okay, I'm kind of trolling with the "Perfect" here, but I use "perfect hash generation" with gperf. ![]() At compiletime I output an input file for gperf and have gperf generate a hash function that can convert an
At compiletime I output an input file for gperf and have gperf generate a hash function that can convert an article name string (the Request URI) to an Index (or to nothing in case the request is invalid).
That Index points directly to the position in a map that it also generates containing the filename that corresponds to the article name. In that way it can fetch the file in a single lookup, and the filesystem is never hit for invalid requests.
My routing.cgi program does the following:
- Read the
Accept-Encodingheader from the client. - If the generated hash function returns the filename: read the HTML into memory.
- If client requested gzip encoding: replace in the HTML javascript and CSS includes with a regex to their
.gz.jsversions. Compress the HTML itself too in the same encoding. - If client requested deflate encoding: do the same with deflate encoding on the HTML, but I currently didn't implement
.defl.jsversions for the Javascript and CSS. - Also after fixing the javascript and CSS includes, compress the HTML now in the same way (gzip or deflate).
- For fun it will add a
X-Compressionheader with compression ratio info. - If the compressed length exceeds the plain version, it will use the plain version.
routing.cgi apache 2.4 config
For now routing.cgi is a simple cgi program, it could be further optimized by making it an apache module, or perhaps using fastcgi.
AddHandler cgi-script .cgi
ScriptAlias /cgi-bin/ "/srv/www/vhosts/blog.cppse.nl/"
<Directory "/srv/www/vhosts/blog.cppse.nl/">
AllowOverride None
Options +ExecCGI -Includes
Order allow,deny
Allow from all
Require all granted
DirectoryIndex /cgi-bin/routing.cgi
FallbackResource /cgi-bin/routing.cgi
</Directory>routing.cpp a few code snippets
1) Determine encoding:
char *acceptEncoding = getenv("HTTP_ACCEPT_ENCODING");
enum encodings {none, gzip, deflate};
encodings encoding = none;
if (acceptEncoding) {
if (strstr(acceptEncoding, "gzip"))
encoding = gzip;
else if (strstr(acceptEncoding, "deflate"))
encoding = deflate;
}2) The hash lookup:
static struct knownArticles *article = Perfect_Hash::in_word_set(requestUri, strlen(requestUri));
if (article) {
printf("X-ArticleId: %d\n", article->articleid);
printf("X-ArticleName: %s\n", article->filename);
printf("Content-Type: text/html; charset=utf-8\n");
....
ss << in.rdbuf();
} else {
printf("Status: 404 Not Found\n");
printf("Content-Type: text/html; charset=utf-8\n");
ss << "404 File not found";
}3) The regexes:
if (encoding == gzip) {
//std::regex regx(".css");
//str = std::regex_replace(str, regx, string(".gz.css"));
const boost::regex scriptregex("(<script[^>]*cdn.cppse.nl[^ ]*)(.js)");
const boost::regex cssregex("(<link[^>]*cdn.cppse.nl[^ ]*)(.css)");
const std::string fmt("\\1.gz\\2");
str = boost::regex_replace(str, scriptregex, fmt, boost::match_default | boost::format_sed);
str = boost::regex_replace(str, cssregex, fmt, boost::match_default | boost::format_sed);
cstr.assign(compress_string2(str));
}4) Compressing to gzip or deflate:
I simply took of Timo Bingmann his {de}compress_string functions, whom use deflate, and created gzip versions of these.
They took me a while to get right, to find the correct parameters etc., so you may find them useful.
You can find them here: Deflate and Gzip Compress- and Decompress functions.
More "performance wins": deferred javascript loading
As a base for the html I use adaptiv.js which provides a grid layout for a responsive design, with the following config:
// Find global javascript include file
var scripts = document.getElementsByTagName('script'),
i = -1;
while (scripts[++i].src.indexOf('global') == -1);
// See if we're using gzip compression, and define config for adaptiv.js
var gzip = scripts[i].src.indexOf('.gz.js') != -1,
rangeArray = gzip
? [
'0px to 760px = mobile.gz.css',
'760px to 980px = 720.gz.css',
'980px to 1280px = 960.gz.css',
'1280px = 1200.gz.css',
]
: [
'0px to 760px = mobile.css',
'760px to 980px = 720.css',
'980px to 1280px = 960.css',
'1280px = 1200.css'
];Only after loading the javascript will it correctly "fix" the right css include, introducing an annoying "flicker" effect. This makes it necessary to require the adaptiv.js javascript asap (a.k.a. in the header of the page).
To fix this I simply added the same css includes with media queries:
<link href='//cdn.cppse.nl/global.css' rel='stylesheet'>
<link href='//cdn.cppse.nl/assets/css/960.css' media='only screen and (min-width: 980px) and (max-width: 1280px)' rel='stylesheet'>
<link href='//cdn.cppse.nl/assets/css/720.css' media='only screen and (min-width: 760px) and (max-width: 980px)' rel='stylesheet'>
<link href='//cdn.cppse.nl/assets/css/1200.css' media='only screen and (min-width: 1280px)' rel='stylesheet'>
<link href='//cdn.cppse.nl/assets/css/mobile.css' media='only screen and (min-width: 0px) and (max-width: 760px)' rel='stylesheet'>Now the javascript in adaptiv.js is only a fallback for browsers that don't support these queries.
All javascript can now be included after DOM elements are loaded/rendered. Nowadays there may be different libraries that don't have this problem. But I'm not up-to-date on that ![]() .
.
As long as you make sure the javascript is loaded after all elements are drawn.
Personally I don't put do that in the <body>'s onload="" attribute, as that is executed after everything on your page is loaded. I prefer to put it right before the body tag closes (</body>), as only the static DOM should have been outputted for the browser.
(You may want your javascript photo-viewer loaded before the very last thumbnail is done loading for example.)
// Now start loading the javascript...
var j = document.createElement('script');
j.type = 'text/javascript';
j.src = '//cdn.cppse.nl/global.' + (gzip ? 'gz.' : '') + 'js?' + version;
document.body.appendChild(j);You can also do this for certain stylesheets, like the print.css perhaps.
Image compression
Another huge gain is of course compressing images. I have PNG, JPG and GIF images. Before I choose a format I already try to choose the most appropriate encoding. Typically PNG or GIF for screenshots, JPG for everything else. In my static site generation, I also optimize all images.
TruePNG + PNGZopfli are the best for lossless compression, see this awesome comparison.
They are windows tools, but they run perfectly with wine, albeit a little slower that's how I use them.
For gifs I use gifsicle (apt-get install gifsicle), and for JPG jpegoptim (apt-get install jpegoptim).
minimize_png:
wine /usr/local/bin/TruePNG.exe /o4 "file.png"
wine /usr/local/bin/PNGZopfli.exe "file.png" 15 "file.png.out"
mv "file.png.out" "file.png"
minimize_jpg:
jpegoptim --strip-all -m90 "file.jpg"
minimize_gif:
gifsicle -b -O3 "file.gif"Excerpt from minimize.log:
compression of file 86-large-thumb-edges.png from 96K to 78K
compression of file 86-edges.png from 45K to 35K
compression of file 86-thumb-edges.png from 38K to 31K
compression of file 600width-result.png from 1,3M to 121K
compression of file 72-large-thumb-userjourney.jpg from 100K to 29K
compression of file 57-large-thumb-diff_sqrt_carmack_d3rsqrt.jpg from 557K to 95K
compression of file 63-result.jpg from 270K to 137K
compression of file 55-large-thumb-vim.jpg from 89K to 27KReplace google "Custom search" with something "faster"
Google's custom search is pretty useful and easy to setup. I did have to do a few nasty CSS hacks to integrate it in my site the way I wanted.
- The advantage is that is does the crawling automatically.
- The disadvantage is that it does the crawling automatically.
- Another disadvantage is that it adds a lot of javascript to your site.
In my case when I search for a keyword "foobar", google search would yield multiple hits:
/index- main page/blog- category/1- paging/foobar- individual article
Wanting more control I switched to Tokyo Dystopia ![]() . You can see it in action when searching via the searchbox on top of the page.
For this to work I now also generate a "searchdata" outputfile alongside the HTML, which is simply the "elaborated" Markdown text. With elaborated I mean code snippets and user comments included.
. You can see it in action when searching via the searchbox on top of the page.
For this to work I now also generate a "searchdata" outputfile alongside the HTML, which is simply the "elaborated" Markdown text. With elaborated I mean code snippets and user comments included.
CSS and Javascript minification
Not going into detail on this one. As a tool I use mince, which by default provides css and js minification with with csstidy and jsmin. For javascript I made a small adjustment to make it use crisp (who is an old collegue of mine)'s JSMin+. Because it's a more advanced minifier that yields even smaller javascript files.
Deferred loading of embedded objects like YouTube videos
I found YouTube/Vimeo & Other flash embeds in my blog posts annoyingly slow. So what I do is put the actual embed code in a container as an HTML comment. For example: I have a custom video player for an mp4 stream like this:
<p><center>
<a class="object_holder" href="#" onclick="videoInLink(this)" style="background:url(//cdn.cppse.nl/83-videothumb.png); width: 750px; height:487px; display:block;">
<!--
<object id="player" classid="clsid:D27CDB6E-AE6D-11cf-96B8-444553540000" name="player" width="750" height="487">
<param name="movie" value="//cdn.cppse.nl/player.swf" />
<param name="allowfullscreen" value="true" />
<param name="allowscriptaccess" value="always" />
<param name="flashvars" value="file=//blog.cppse.nl/videos/wxhttpproxy.mp4&repeat=never&shuffle=true&autostart=true&streamer=lighttpd&backcolor=000000&frontcolor=ffffff" />
<embed
type="application/x-shockwave-flash"
id="player2"
name="player2"
src="//cdn.cppse.nl/player.swf"
width="750"
height="487"
allowscriptaccess="always"
allowfullscreen="true"
flashvars="file=//blog.cppse.nl/videos/wxhttpproxy.mp4&repeat=never&shuffle=true&autostart=true&streamer=lighttpd&backcolor=000000&frontcolor=ffffff"
/>
</object>
-->
</a>
</center></p>The object_holder displays a screenshot of the player, giving the illusion it's already loaded. Only when the user clicks the screenshot the commented <object> is inserted using the videoInLink javascript function.
function videoInLink(anchor)
{
anchor.innerHTML = anchor.innerHTML.replace('<!--','').replace('-->','');
anchor.removeAttribute('href');
anchor.onclick = null;
return false;
} The end
Concluding my ramblings, I hope you may have find something of use in this post.
Created a "Lame PHP Parser" that in this picture visualizes it's own sourcecode!
I thought the output was pretty cool.
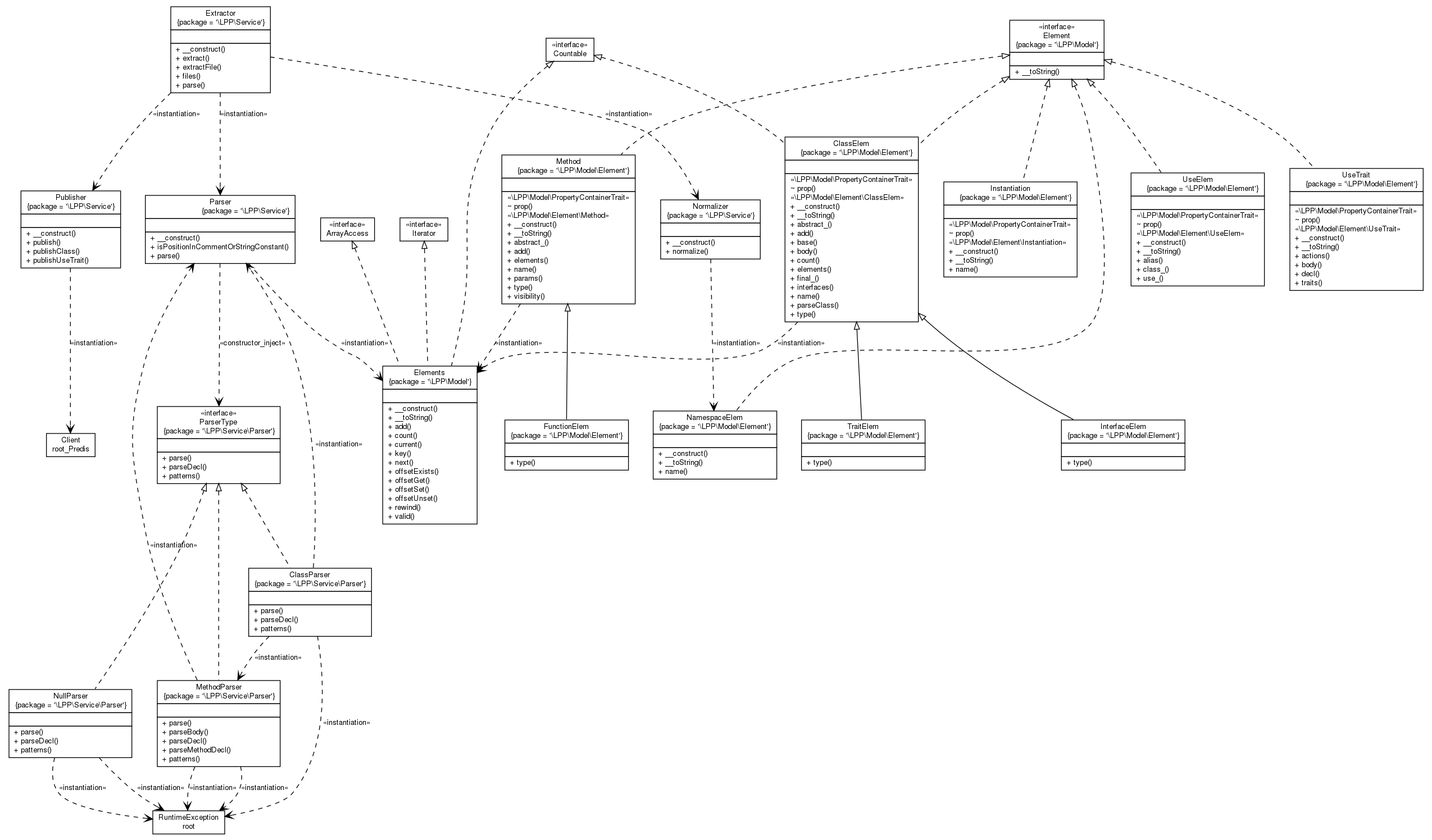
It's not the most efficient code, which is fine for my current use case. I was wondering if I could speed it up with Facebook's HHVM (HipHop VM), a PHP virtual machine.
HipHop VM executes the code 5,82 times faster!(*)
Parsing the Symfony code in my 'vendor' directory, takes ~57 seconds with the PHP executable provided by Ubuntu.
PHP 5.5.3-1ubuntu2.1 (cli) (built: Dec 12 2013 04:24:35)
Copyright (c) 1997-2013 The PHP Group
Zend Engine v2.5.0, Copyright (c) 1998-2013 Zend Technologies
with Zend OPcache v7.0.3-dev, Copyright (c) 1999-2013, by Zend TechnologiesBenchmarks from three successive runs:
- real 0m57,34s, user 0m56,75s, sys 0m0,29s
- real 0m57,18s, user 0m56,58s, sys 0m0,28s
- real 0m58,38s, user 0m57,72s, sys 0m0,34s
Parsing the same directory three times with hhvm.
HipHop VM 3.0.1 (rel)
Compiler: tags/HHVM-3.0.1-0-g97c0ac06000e060376fdac4a7970e954e77900d6
Repo schema: a1146d49c5ba0d6db903beb3a4ed8a3766fef182Benchmarks from three successive runs:
- real 0m9,86s, user 0m9,04s, sys 0m0,54s
- real 0m9,85s, user 0m9,15s, sys 0m0,45s
- real 0m9,74s, user 0m9,06s, sys 0m0,44s
(*) 57.34 / 9.86 = 5,815415822
Solving the puzzle at PHPBenelux 2014

Last conference at the Dutch PHP Conference (DPC) I wrote a summary (in Dutch). This time I couldn't find the time, I took notes though, but I was/am too lazy. For PHP Benelux 2014 experiences you can read on other people their blogs, for example the one David wrote at his blog. And if you're looking for sheets, chances are you can find them at the event's joind.in page.
I made one big mistake at PHPBenelux, that was missing (by accident (don't ask why :p)) Ross Tuck's talk. Was really curious about that one. Of the other talks I especially liked Bastian Hofmann's talk "Marrying front with back end". His talk at DPC was also very good IIRC.
Dutch web alliance puzzle
An old collegue of mine (Marijn) and I decided to programmatically solve the puzzle created for the event there DWA. You can find the puzzle instructions in the photo I took (see fig.2.) We heard a rumour that you could win an ipad if you solved it. Unfortunately that wasn't true . In short you have to place all cubes side-by-side in such a way that rotating them combined should yield four unique labels each rotation step. There is only one possible solution.
We decided both on different approaches and see who would solve it first. Challenge accepted! I lost unfortunately, I even had to abandon my first approach and made the switch to semi-brute-force as soon as I gained more insight in how it could be solved more easily this way. Marijn approached it brute force from the start.
I gave each cube a number {1, 2, 3, 4}, and each sidename a letter {a, b, c, d, x, y}. Next I defined for each cube three directions {a, b, c, d}, {x, b, y, d} and {x, c, y, a} (see fig.1.). All these directions can also be in reverse ({d, c, b, a}, ...).
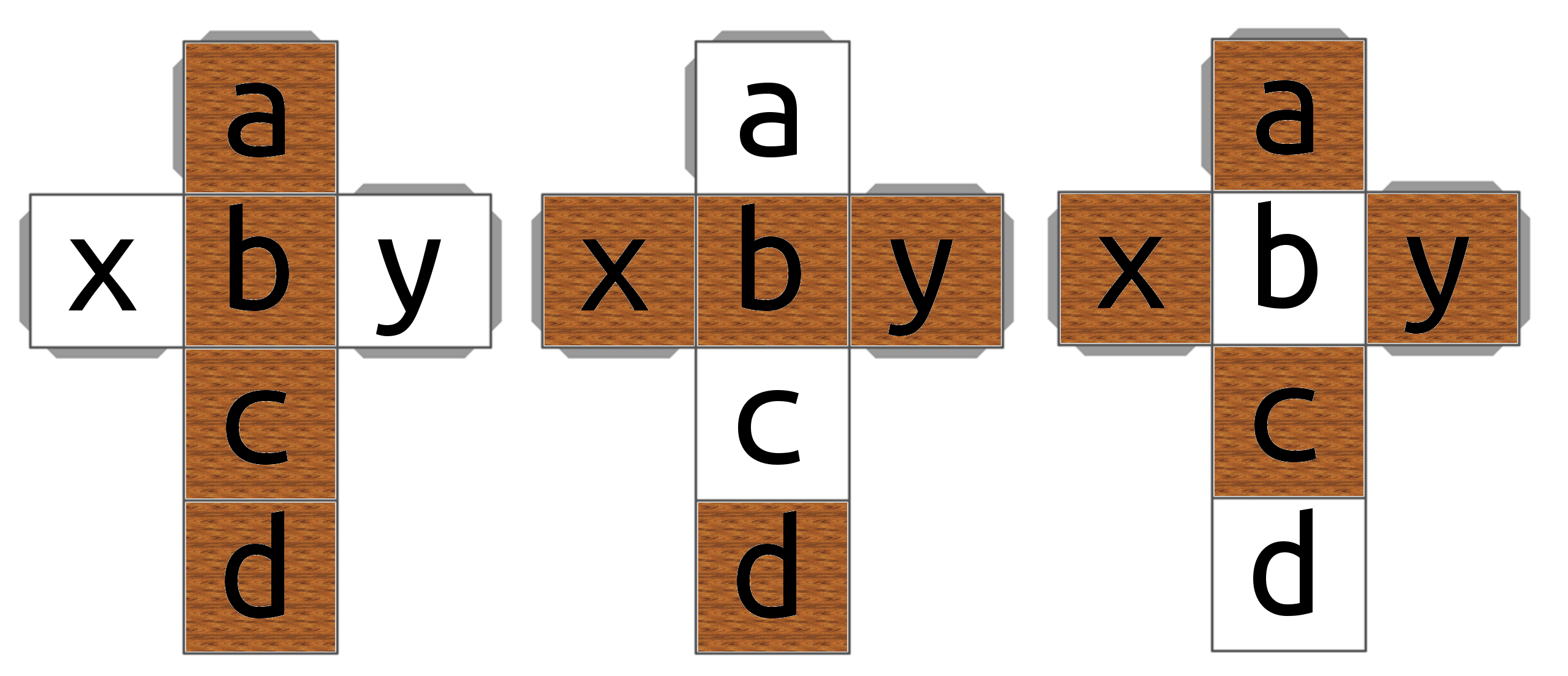

My first idea was to place a cube on a side randomly, choosing for each cube a random direction to rotate in, and try four rotation steps. If in all steps the pictures were unique that would be a solution.
I made a mistake in the implementation, totally forgot that {x, c, y, a} is also a possible sequence. What also didn't help is that I misread the instructions at first, thinking all sides had to be equal (instead of not-equal), which isn't possible if you take a good look at the actual cubes. I guess beer + coding isn't always a good combination.
My second approach was simply, generate "layouts" for each cube's three directions, i.e. for {a, b, c, d}:
{a, b, c, d}{b, c, d, a}{c, d, a, b}{d, a, b, c}{d, c, b, a}{c, b, a, d}{b, a, d, c}{a, d, c, d}
For each cube a, b, c, d mean different side types (the different logos, php, phpbenelux, dwa, phpelephant). I simply compare every combination, and filter out the duplicate results. You initially get eight solutions, because every solution you can start at the first, second, third or fourth "step" of the solution, and eight because of the extra "times two" multiplier you get for forward versus backward rotation.
Solver in C++
Code also available on http://ideone.com/ttFYMD.
#include <iostream>
#include <algorithm>
#include <stdexcept>
#include <string>
#include <sstream>
#include <vector>
#include <array>
#include <iomanip>
enum class sidename
{
a, b, c, d, x, y
};
enum class sidetype
{
phpbenelux, php, phpelephant, dwa
};
std::string sidename_str(sidename sn) {
switch (sn) {
case sidename::a: return "a";
case sidename::b: return "b";
case sidename::c: return "c";
case sidename::d: return "d";
case sidename::x: return "x";
case sidename::y: return "y";
}
throw std::runtime_error{"invalid sidename"};
}
std::string sidetype_str(sidetype st) {
switch (st) {
case sidetype::phpbenelux: return "phpbenelux";
case sidetype::php: return "php";
case sidetype::phpelephant: return "phpelephant";
case sidetype::dwa: return "dwa";
}
throw std::runtime_error{"invalid sidetype"};
}
/**
* cubes define 6 side types (or pictures)
*
* cubes calculate for themselves all possible layouts, meaning
* if you rotate them into some direction, you get a side, followed by side+1, side+2, side+3.
* there are a few possibilities: reverse order, and in each layout (or "path") you can start
* rotating the cube on side, side+1, side+2 or side+4 (starting point "shifts").
*/
class cube
{
public:
cube(sidetype a, sidetype b, sidetype c, sidetype d, sidetype x, sidetype y)
: a_{a}, b_{b}, c_{c}, d_{d}, x_{x}, y_{y},
directionnames_({{
{sidename::a, sidename::b, sidename::c, sidename::d},
{sidename::x, sidename::b, sidename::y, sidename::d},
{sidename::a, sidename::y, sidename::c, sidename::x} }}),
directions_({{ {a, b, c, d}, {x, b, y, d}, {a, y, c, x} }})
{
for (int i=0; i<4; i++) {
for (auto &sides : directions_) {
// normal insert
layouts_.push_back(sides);
// reverse insert
auto sidesrev = sides;
std::reverse(std::begin(sidesrev), std::end(sidesrev));
layouts_.push_back(sidesrev);
// shift all
sidetype temp = sides[0];
for (int i=1; i<=3; i++)
sides[i - 1] = sides[i];
sides[3] = temp;
}
}
}
const std::vector<std::array<sidetype, 4>> & layouts() { return layouts_; }
private:
/**
* This is how I labeled each sidetype:
*
* X = a
* X X X = x b y
* X = c
* X = d
*/
sidetype a_;
sidetype b_;
sidetype c_;
sidetype d_;
sidetype x_;
sidetype y_;
std::array<std::array<sidename, 4>, 3> directionnames_;
std::array<std::array<sidetype, 4>, 3> directions_;
std::vector<std::array<sidetype, 4>> layouts_;
};
/**
* helper class that can see if a given solution is a duplicate from a previous solution
*
* if you have a solution that is simply the same one, but rotating in a different direction
* is not really a new solution. also note the four possible starting point in each layout/path.
* so it will check if duplicates exist in both forward and backward directions, and for each
* possible four shifts
*/
class solutions
{
public:
solutions()
{}
bool is_dupe(std::array<std::array<sidetype, 4>, 4> temp2)
{
// Check if found solution isn't a duplicate
bool duplicate = false;
for (auto &solution : solutions_) {
for (int j=0; j<8; j++) {
duplicate = true;
int sidenum = 0;
for (auto &side : solution) {
auto &temp = temp2[sidenum++];
int count = 0;
int offset = j % 4;
if (j < 4) {
// Check if they are duplicates, as we use offsets of +0, +1, +2, +3 we can
// detect shifted duplicate results.
for (auto i = side.begin(); i != side.end(); i++) {
duplicate = duplicate && temp[(count + offset) % 4] == *i;
count++;
}
}
else {
// Check if they are duplicates simply in reverse order, also with the
// detect for shifted duplicates.
for (auto i = side.rbegin(); i != side.rend(); i++) {
duplicate = duplicate && temp[(count + offset) % 4] == *i;
count++;
}
}
}
if (duplicate)
return true;
}
}
// Remember found solution, for duplicates checking
solutions_.push_back(temp2);
return false;
}
private:
std::vector<std::array<std::array<sidetype, 4>, 4>> solutions_;
};
int main (int argc, char *argv[])
{
/*
* on the sheet:
*
* cube 4 (sideways)
*
* cube 1, 2, 3
*/
cube one{
sidetype::dwa,
sidetype::phpelephant,
sidetype::phpbenelux,
sidetype::dwa,
sidetype::php,
sidetype::phpbenelux};
cube two{
sidetype::phpelephant,
sidetype::phpbenelux,
sidetype::phpbenelux,
sidetype::phpbenelux,
sidetype::php,
sidetype::dwa};
cube three{
sidetype::phpbenelux,
sidetype::dwa,
sidetype::phpelephant,
sidetype::php,
sidetype::dwa,
sidetype::phpelephant};
cube four{
sidetype::php,
sidetype::phpelephant,
sidetype::phpbenelux,
sidetype::phpelephant,
sidetype::dwa,
sidetype::php};
solutions solution;
for (auto &cube1sides : one.layouts()) {
for (auto &cube2sides : two.layouts()) {
for (auto &cube3sides : three.layouts()) {
for (auto &cube4sides : four.layouts()) {
// Pictures have to be unique on each four cubes to be considered a unique solution..
bool flag = false;
for (int i=0; i<4; i++) {
// .. Also on each four rotations of course
flag = flag || (!(cube1sides[i] != cube2sides[i] &&
cube1sides[i] != cube3sides[i] &&
cube1sides[i] != cube4sides[i] &&
cube2sides[i] != cube3sides[i] &&
cube2sides[i] != cube4sides[i] &&
cube3sides[i] != cube4sides[i]));
}
if (!flag){
// Skip duplicate solutions
if (solution.is_dupe({cube1sides, cube2sides, cube3sides, cube4sides})) {
continue;
}
// Print the result
std::cout << "The cube-layout for the solution:" << std::endl << std::endl;
static auto print = [](const std::string &cube, decltype(cube1sides) &sides) {
std::cout << cube << ": "
<< " front: " << std::setw(15) << sidetype_str(sides[0]) << ", "
<< " up: " << std::setw(15) << sidetype_str(sides[1]) << ", "
<< " top: " << std::setw(15) << sidetype_str(sides[2]) << ", "
<< " back: " << std::setw(15) << sidetype_str(sides[3])
<< std::endl;
};
print("cube #1", cube1sides);
print("cube #2", cube2sides);
print("cube #3", cube3sides);
print("cube #4", cube4sides);
}
}}}}
}
Output:
cube #1: front: php, up: phpelephant, top: phpbenelux, back: dwa cube #2: front: phpbenelux, up: dwa, top: phpelephant, back: php cube #3: front: phpelephant, up: phpbenelux, top: dwa, back: phpelephant cube #4: front: dwa, up: php, top: php, back: phpbenelux

Performance is on my pc 0,00202 seconds on average per run (see perf.txt). The average is 0,00181 seconds, 11.60% faster, if we stop processing when we find the 'first' solution.
I still think my first idea should also work and I'm curious if that "random brute-force" algorithm would on average find a solution faster compared to finding the first solution in my current solver (in terms of required compares). .
Serving specific requests from a mutable cache
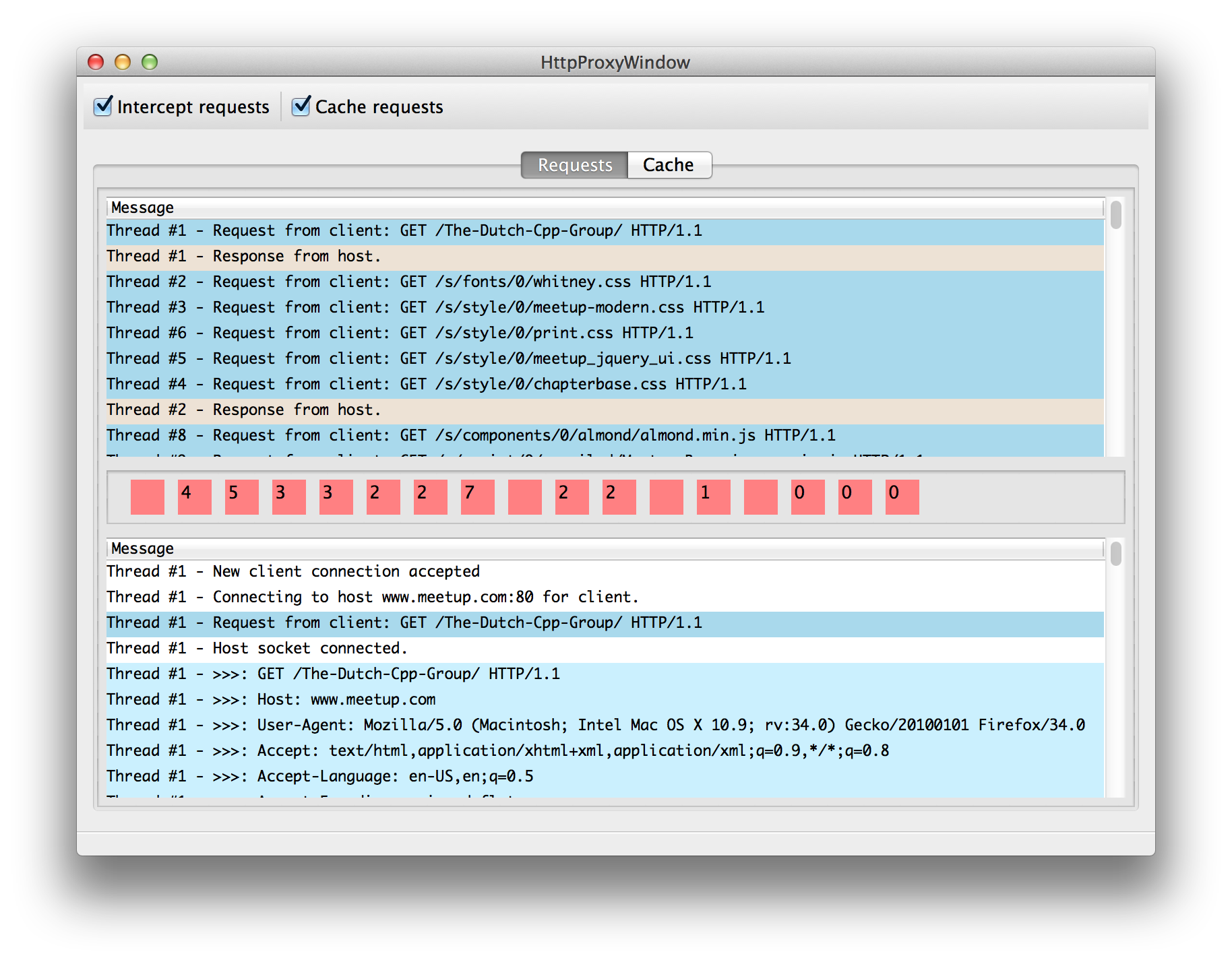
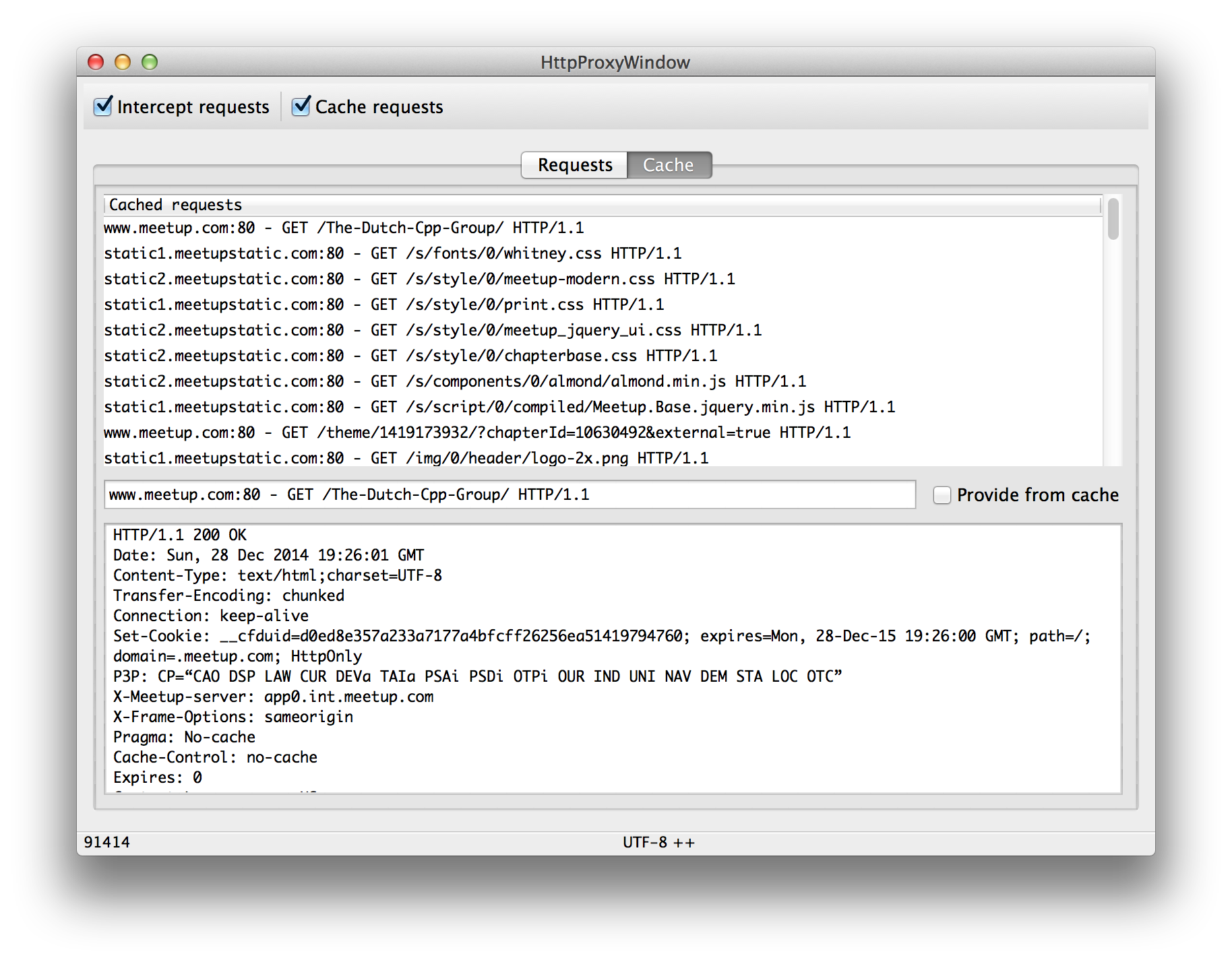
You can record requests now in a new tab "Cache", and you can choose to use this cache per request. Any such request will be immediately returned from the cache (instead of being proxied).
The cool thing is that you can modify the cache, so modifying CSS / Javascript is easy for example. I wanted this feature so I can debug some stuff on environments other than development. There are other ways to do this, but I think this is very convenient.
Some use cases
- Change
<script src=...includes to URL's from production to your dev environment, to simply test javascript on production pages. - Change javascript includes to their unminified / deobfuscated versions..
- Add 'debugger' / console.log's to the source.
- I've used it to more conveniently debug www.google-analytics.com/ga.js (an obfuscated javascript), by de-obfuscating it and using the step debugger in chrome.
By the way, a cool way to set a breakpoint in Javascript on specific function calls could be this.
In ga.js there is a _gaq array, with a push function _gaq.push([something]);, I simply added this with wxhttpproxy in ga.js:
var foo = _gaq.push;
_gaq.push = function () {
debugger; <<<<< and the debugger will intercept, you can view the stacktrace
return foo.apply(_gaq, arguments);
}Features / Roadmap
Note that the wxhttpproxy will intelligently modify the Content-Length header in case you modify the content. Content-Encodings gzip/deflate are not yet supported, for the time-being the proxy will garble the Accept header (by replacing gzip -> nogz, and deflate -> noflate). This is a workaround, that makes sure gzip/deflate isn't used.
Supported for chunked encoding should be added (easy), you can already edit it manually, just remove the chunked header, the hex numbers and add a Content-Length to work around it.
Real support for gzip / deflat should be added. I already have code for gzip / deflate support laying around somewhere.
Download
As an Ubuntu/debian package available here.
- It uses wx2.8. In wx3.0 the event model has changed a bit, and I believe there is an error in the event handling w/regards to sockets. I will post some more details on this later, and if I have the time see if I can fix it..

My super awesome NVIDIA Quadro K600 doesn't work properly with the default video drivers in Linux mint 15, 16 or Ubuntu 13.10.
Especially in mint it was especially unstable. In Ubuntu everything seems fine for a few days, until the GPU finally crashed as well.
Linux mint 15 / 16
You disable the default driver called nouveau, to be loaded by the kernel with nouveau.blacklist=1.
In mint I've tried editing GRUB_CMDLINE_LINUX etc. in /usr/share/grub/default/grub and all of /etc/grub.d/*. Somehow update-grub didn't parse it, I was not so patient, so I ended up simply editting /boot/grub/grub.cfg.
trigen@Firefly21 ~ $ vim /boot/grub/grub.cfg
...
:g/^\s*linux
linux /boot/vmlinuz-3.8.0-19-generic root=UUID=60f8754f-f688-461e-b120-bf8402c1e2a9 ro nouveau.blacklist=1
linux /boot/vmlinuz-3.8.0-19-generic root=UUID=60f8754f-f688-461e-b120-bf8402c1e2a9 ro recovery nomodeset nouveau.blacklist=1
linux16 /boot/memtest86+.bin
linux16 /boot/memtest86+.bin console=ttyS0,115200n8
Press ENTER or type command to continueReboot the system. CTRL+ALT+F1, login, sudo service mdm stop, ./NVIDIA-Linux-x86_64-331.20.run and follow instructions. Reboot.
Ubuntu 13.10
In ubuntu I attempted to directly edit /boot/grub/grub.cfg again. Adding the blacklist parameter, somehow this failed, the NVIDIA installer still complaining about nouveau being loaded.
So I attempted the 'normal approach' again: vim /etc/default/grub, modified this line: GRUB_CMDLINE_LINUX_DEFAULT="quiet splash nomodeset nouveau.blacklist=1".
I also googled and found this answer on stackoverflow, suggesting the nomodeset is necessary as well. (So I added both). sudo update-grub and EAT REBOOT INSTALL REPEAT.
Reboot the system. CTRL+ALT+F1, login, sudo service lightdm stop, ./NVIDIA-Linux-x86_64-331.20.run and follow instructions. Reboot.
Some notes: Install grub into specific partition
This is a "Note to self", how to install grub for specific partition (source). I needed this command fixing my dual boot (linux and windows on one ssd).
sudo mount /dev/sda5 /mnt
sudo grub-install --root-directory=/mnt/ /dev/sda
sudo update-grubSomehow linux mint f*cked up my boot to windows 8 partition. It had some problems recognizing my partition table or something. (At work I have the exact same setup, and there were no problems.) I ended up fixing it with the above command, and from windows (had to restore an image) using this tutorial that uses EasyBCD.
Settings for Tide graph Casio G-Shock GLX 150
Deploying owncloud via Helm on Kubernetes
How to print an endlessly folding card
i3 floating point window resize percentage wise and centered
My visit to Meeting C++ 2016!
Kerberizing Cloudera Manager
How to screen capture in Windows 10 with HiDPI support
Profiling and visualizing with GNU strace
How to "inspect element" XUL applications
How to debug XUL applications
Circlix Clock
Improve performance Jetbrains IDE when working on remote machine
Enable fsnotifier for Jetbrains IDE's like PyCharm over NFS/SSHFS network share
Nagios 4 + Nagvis + Nagiosgraph + Nagios plugins Dockerfile / Docker image
Qt Applications in Browser
Tweak Battle....
Example rendered video
Zend server And the Return of the Oracle Instant Client
Visualize Issue Ranks in Atlassian Jira Agile board
PhpStorm or IntelliJ suddenly hangs / freezes / keyboard not responsive/ unresponsive while editing in Linux / Ubuntu
Deflate and Gzip compress and decompress functions
Optimizing your website for performance
Lame PHP Parser, visualization and how cool hhvm is!
PHP Benelux 2014
Use cache in http proxy for debugging in webdevelopment
Install NVIDIA proprietary drivers in Ubuntu 13.10 or Linux mint 15/16
Free HTTP proxy for debugging purposes with GUI
Away- nicknames coloring in nicklist mIRC
Visual studio shortcut keys / settings
Raspberry pi camera streaming with crtmpserver test
Video streaming from code with SFML and ffmpeg
![nl][] Dutch PHP Conference 2013
![nl][] Tweakers fotoalbum images uploader
sanitizer - a shortcut key app with explorer integration
benchmarklib: a small benchmarking library
![nl][] watermarker tool
Fixing slow phpmyadmin by rewriting queries using mysql-proxy
ksh "pushd .", "popd" and "dirs" commands
Generating gradients
spf13 vim distribution
phpfolding.vim : Automatic folding of PHP functions, classes,.. (also folds related PhpDoc)
Visualizing (inverse) square root optimizations
Configure highlight weechat in screen and putty
Meta log monitor (or scriptable tail with GUI)
Firefox select behaviour and H264 support
Cool way to provide multiple iterators for your class (C++)
X, Y to Latitude + Longitude functions for (google) maps
PhpStorm and Ideavim {Escape,C-c,C-[} responsiveness
Tweakers logo test
Firebird IBPP use in non-unicode project
Automatic nickname in channel and nicklist colouring in mIRC
Allegro 5 separate process for rendering
Allegro 5 and wxWidgets example
Proxy securely through ANY corporate proxy/firewall
GNU Screen Navigator V2
Some CGI "tips"
Inline printf compatible with char *
Render on top of mplayer using custom window
Starcry rendered videos
Behaviours engine
DialogBlocks Howto
Compiling with DialogBlocks
Git, github, Mercurial, bitbucket
SuperMouser - mouseless navigation
Collection of wallpapers
BASE64 COMMANDLINE
Singleton notepad.exe
Starcry rendered frame images
GNU Screen Navigator
PHP debugging in practice!
Photoshop blenders for allegro
Launch of yet another blog ii
Common Lisp wallpaper
Improving the outline for the Adornment of the Middle Way
Using allegro with wxWidgets
Launch of yet another blog
Motion blur
Functional programming
Enable wake-on-lan on Linux Debian (4.0)

Topics:
Other interests:
EBPF Flamegraphs C++ Ubuntu 20.04
Site generated using ![]() ArticleManager © 2010-2013
ArticleManager © 2010-2013
